在 前一篇使用小记 中,我记录了如何利用Docker安装运行 Graylog 、如何设置配置文件、如何使用Graylog的输入流、提取器、事件和告警,并在最后记录了我个人对提取器、筛选和事件的理解。
我对这个产品还有一些地方比较好奇:
-
第一个问题是我在上一篇的分析当中遗留的: ⌈ 不过还是有个小bug,事件聚合的时候只能考虑具有 相同源IP 的登录失败日志,不过这一点可能是Graylog的进阶用法,今天还没探索到这个地步 ⌋
-
第二个问题,如何把事件串联起来。例如在对 暴力破解成功 进行告警时,我们首先要产生一个 暴力破解 的事件,这个事件当中可能包含比如说
10条的登录失败日志,紧接着要产生一个 登录成功 事件,这个事件只需要由一条登录成功日志来触发;这两个事件先后发生时,就代表了 暴力破解成功 的情况。
0 预设环境
今天,我打算以真正的Linux上的SSH日志为例,来研究一下Graylog要如何处理以上两个问题。
日志样例:
Jul 12 06:09:43 combo sshd(pam_unix)[4048]: authentication failure; logname= uid=0 euid=0 tty=NODEVssh ruser= rhost=68.143.156.89.nw.nuvox.net user=root
Jun 30 22:16:32 combo sshd(pam_unix)[19434]: session opened for user test by (uid=509)
对应配置了一系列提取器:
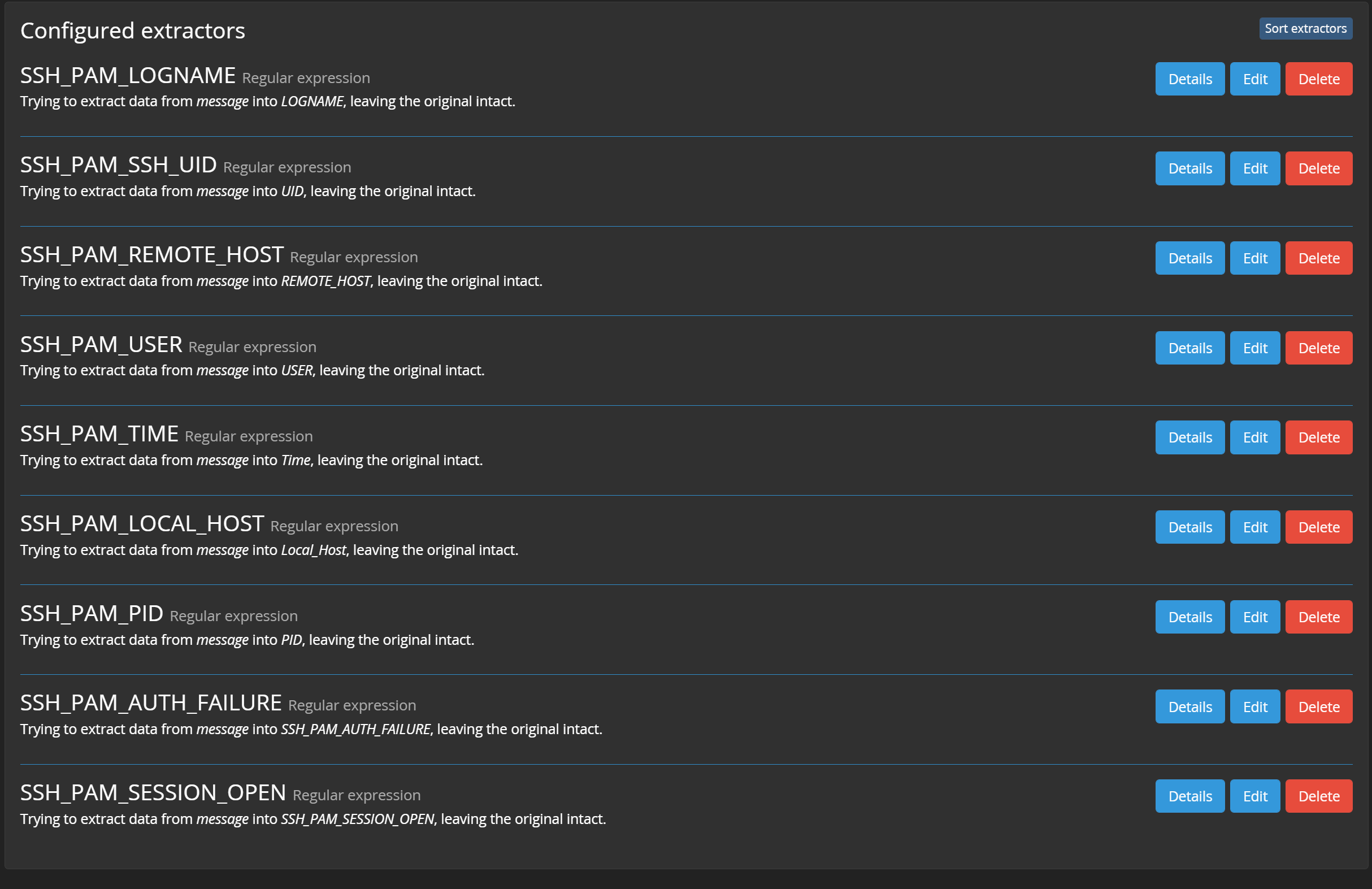
其中只有 SSH_PAM_SESSION_OPEN 是用于匹配登录成功的日志,其余提取器均用于登录失败日志。
这里有一个我比较不满意的点,就是配置正则提取器的时候只能提取出 第一个 匹配组(match group);当我希望从登录失败日志当中提取较多信息的时候,就要配置很多个提取器(比如上图当中配置了提取远程主机、用户名、时间、进程ID等信息的提取器),这些提取器用的其实都是同一个正则,完全没必要进行这么多冗余配置。
上图中有两个提取器值得展开说明,它们是 SSH_PAM_AUTH_FAILURE 和 SSH_PAM_SESSION_OPEN :


可以看到,这两条正则其实就是把整个消息体都匹配出来,放到了对应的自定义字段里。这样做的意义是便于使用我们在 前一篇使用小记 当中提到的筛选方式 _exists_: [xxx] 来筛选出所有满足正则的消息,相当于绕了个弯来实现 正则筛选 ,这么做的原因是按照官方Demo来写正则筛选语句根本筛不到对应的日志,我觉得没必要浪费时间来研究这种不属于我的问题。
1 聚合
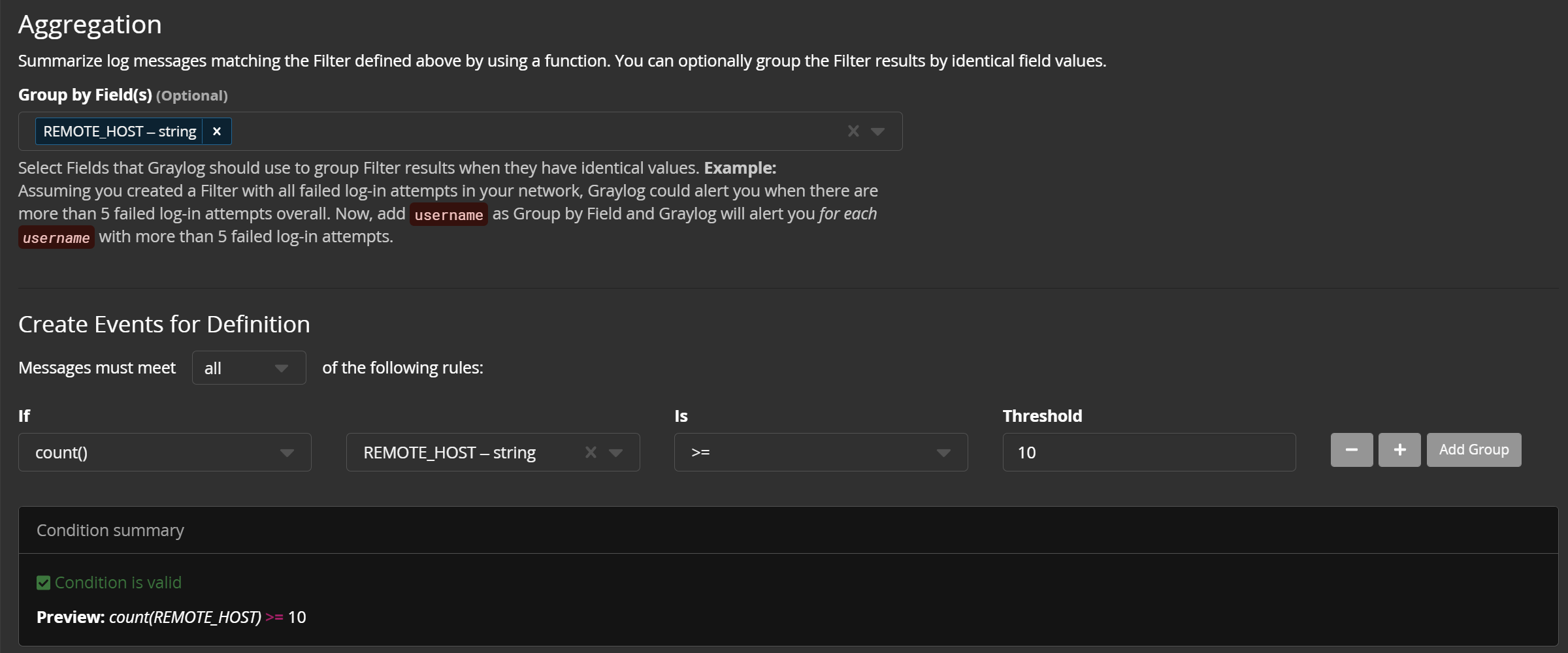
在前一篇使用小记当中,我提到对于SSH暴力破解攻击来说,只有登录失败日志都来自于 同一IP 才有意义,否则可能由于多用户并发登录失败引发系统误报。此外,也不能每一条登陆失败日志就触发一次事件告警,而应该等到登录失败日志出现了比如说 10 次以后,再产生一条告警。
这样的功能可以通过 事件聚合 来实现。在定义事件的【Filter & Aggregation】一栏当中,可以配置聚合设置,例如对于登录失败日志,我们以 REMOTE_HOST 即SSH登录的源主机名来作为分类,并为源主机名配置一个阈值 10 ,这样,仅当来自 某个 主机的SSH登录失败次数达到 10 以上时,才会产生一条事件。
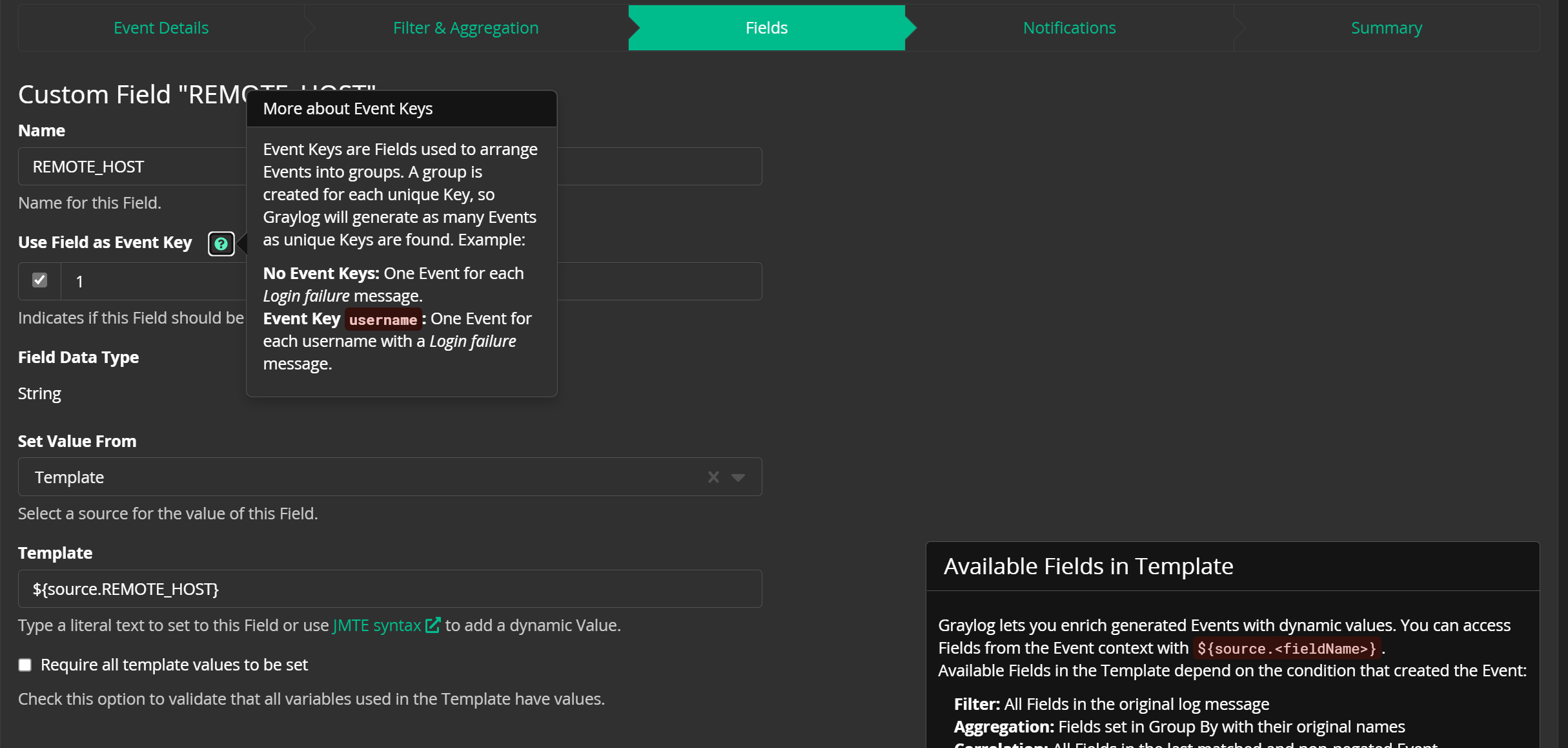
此外,在【Fields】一栏中添加 REMOTE_HOST 字段,并把这个字段设置为 key 。
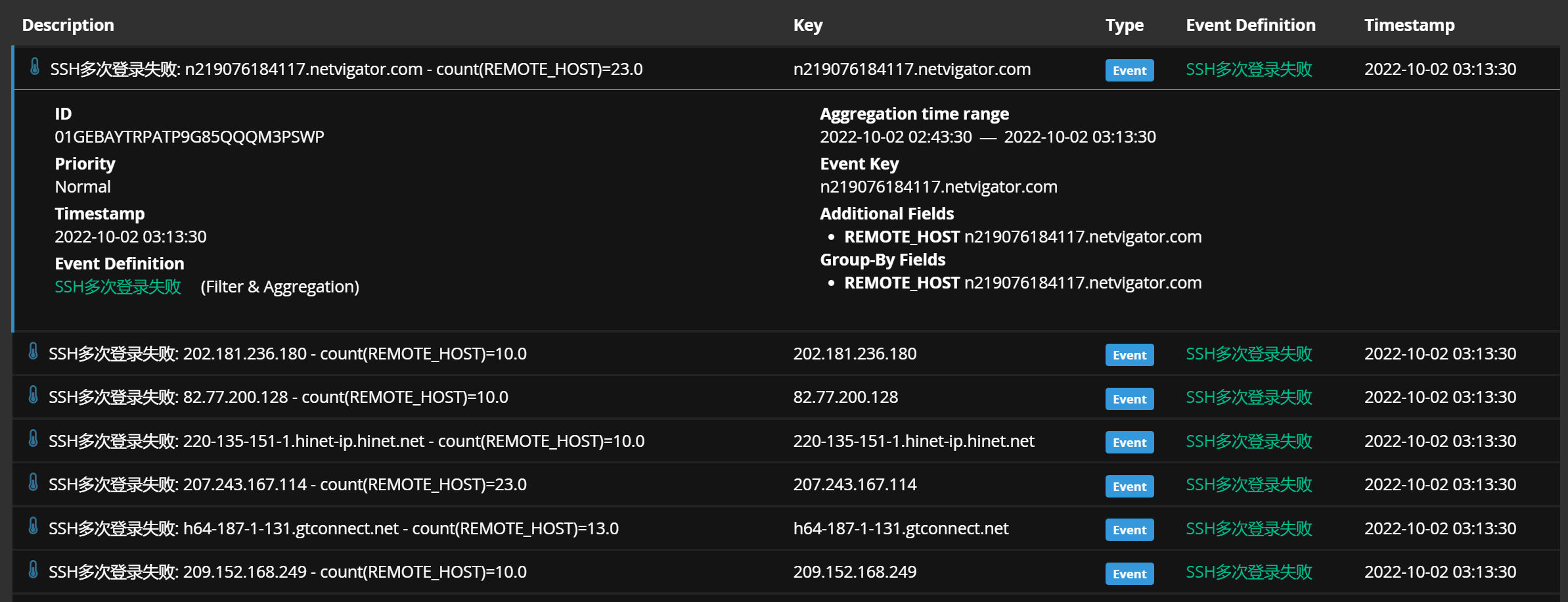
一切就绪之后,把日志打到输入流中 cat linux_log.log | nc 127.0.0.1 1514 :
2 关联
其实事件关联是我最期待实践的功能,however:
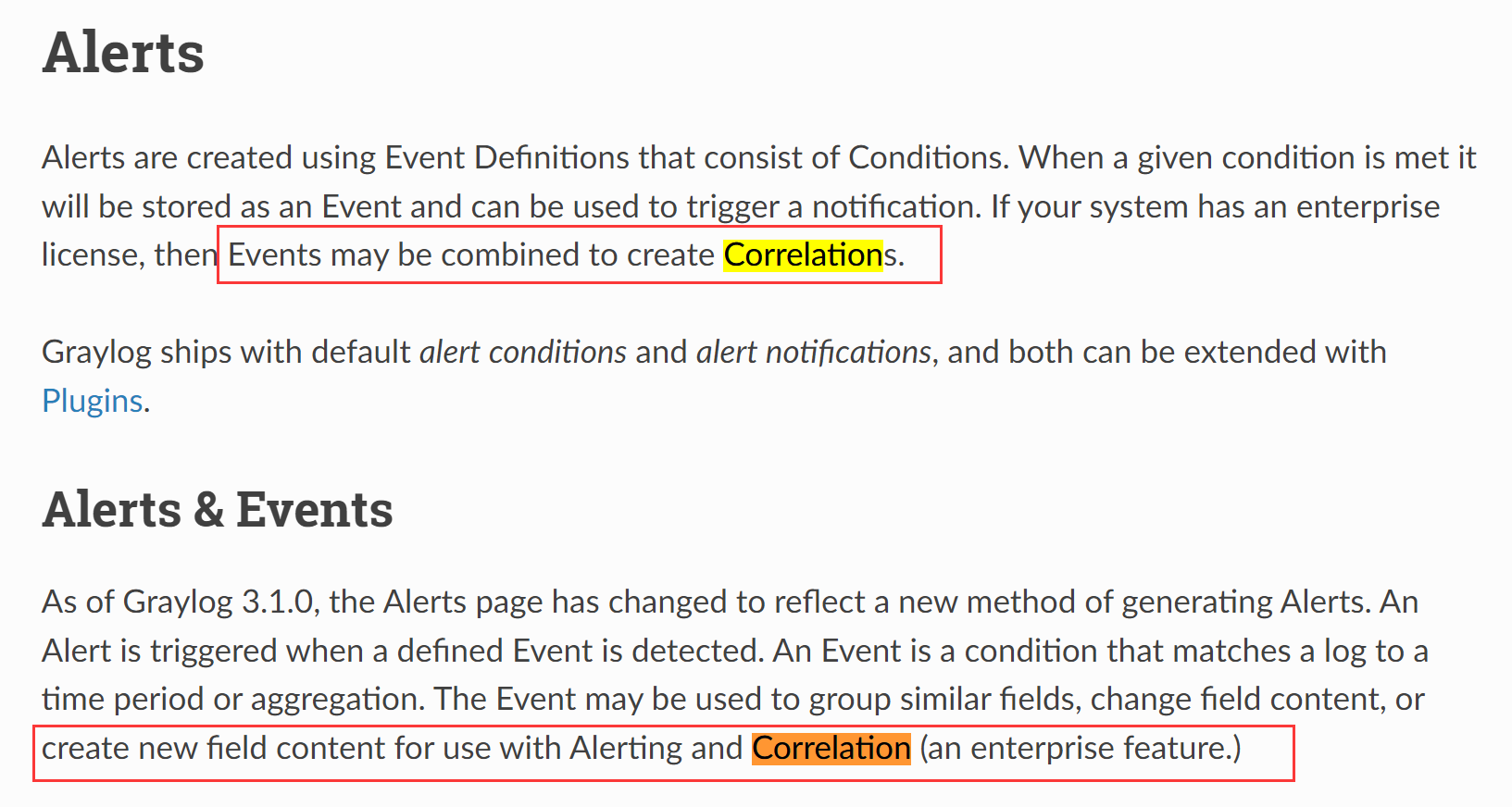
寄!
其实我研究Graylog的初衷就是为了提高工作当中问题定位的效率,事件关联是一项非常有用的功能,它能够帮助我们定义出符合业务逻辑的事件链条,令我们更好地从日志当中提取出有效信息。不过,既然是高级功能,玩不到的话也就罢了,至此所体验的这些,大概也比手动搜索keyword要强上许多,还是期待它投入实战的那天罢。