背景
最近在工作中发现我们基本采取一种DevOps的工作方式,开发即运维,有时一个问题要定位很久,维测能力非常差。
造成维护困难的原因有很多,我认为有几点比较重要:
-
代码稳定性差。这个问题对于一个发展初期的业务来说比较常见,只能说尽力避免。
-
日志太多。开发人员写代码的时候总是毫不吝惜日志打印操作,这些信息对于某一个功能来说可能很全面,但在一个完整的模块里面,这会带来超级多的噪声。
-
原始的分析方式。
因此我希望找一个能够方便地分析庞杂的日志数据的工具,试图减轻运维的压力。经过简单的选型,决定试一试 Graylog ,本文小作记录。
Step 0 环境配置
预装:WSL2 + Ubuntu22.04 + Windows Terminal
docker on WSL2
下载 Docker Desktop for Winodws ,傻瓜式安装。
首先设置启用WSL支持:
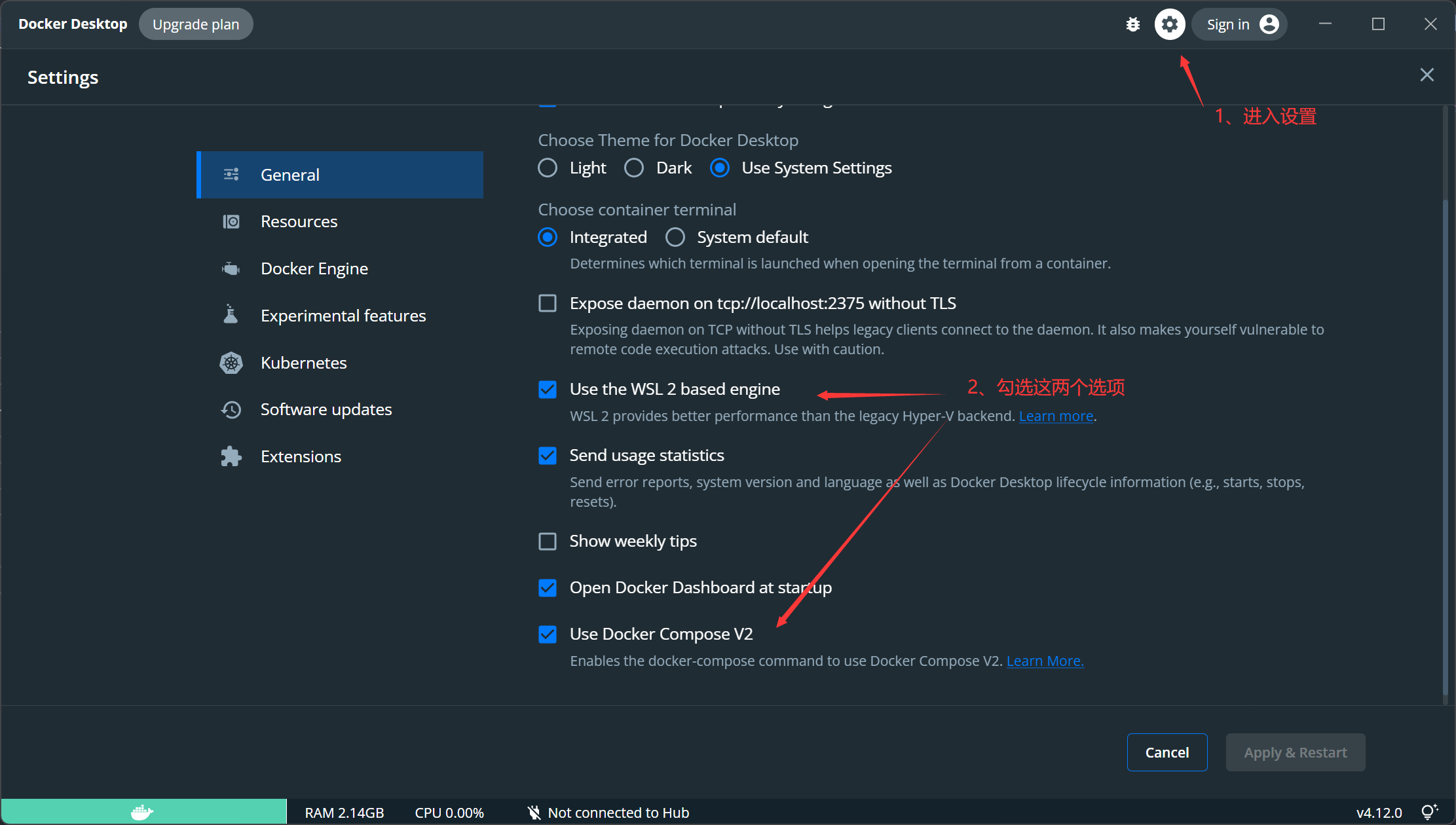
接着进入 阿里云镜像加速 搞一个加速器,然后在Docker Desktop【Docker Engine】一栏里面配置加速器地址:
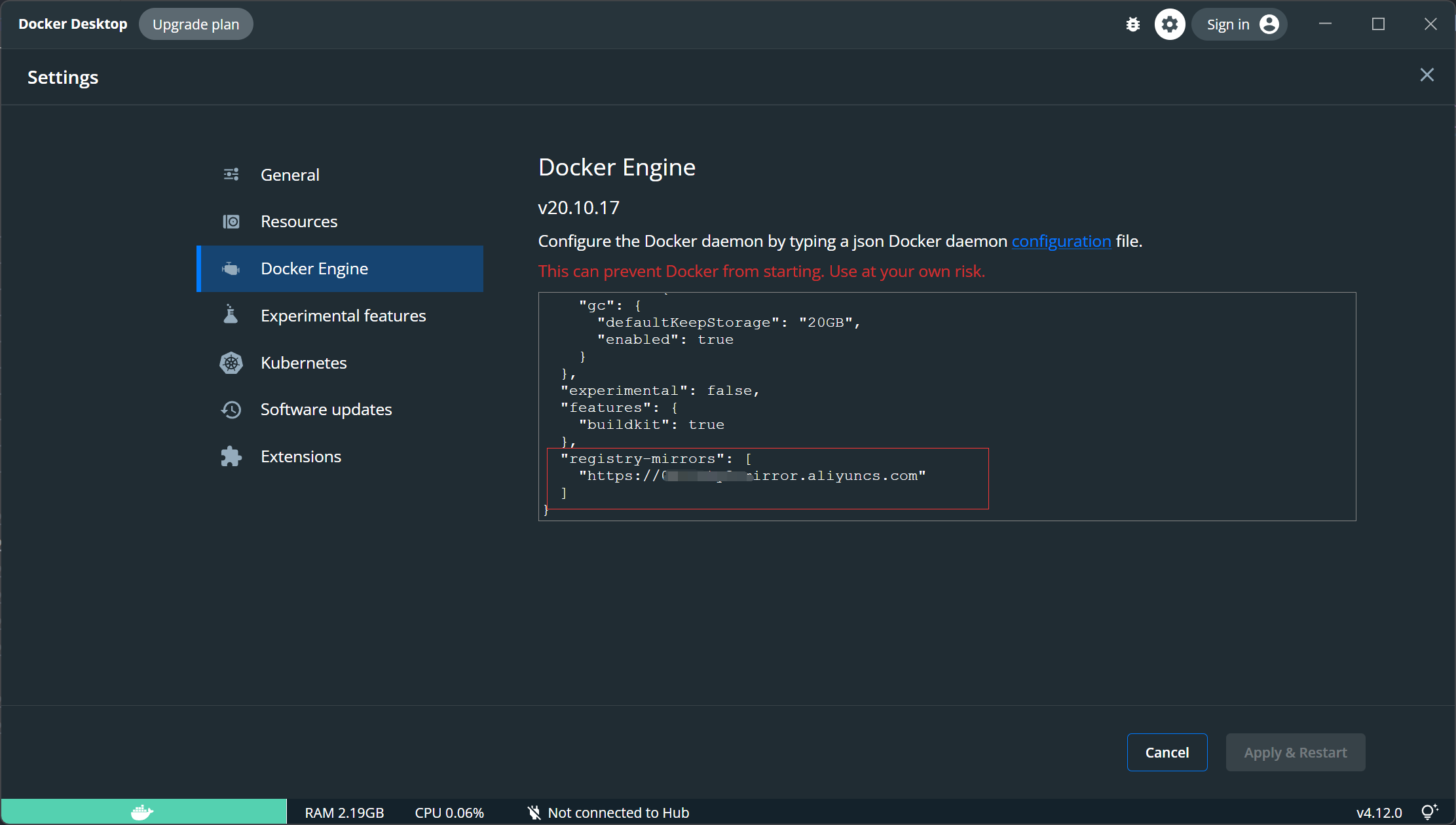
点击右下角 Apply & Resatrt 即可。
另一种在WSL2上安装docker的方法:
按照 参考资料[2] 所说的,我们也可以在WSL上直接执行以下命令:
$ curl -fsSL https://get.docker.com -o get-docker.sh $ sudo sh get-docker.sh $ sudo service docker start这里我并未实践,仅供读者参考。不过,作者的提醒很有参考价值:
注意:不同于完全linux虚拟机方式,WLS2下通过apt install docker-ce命令安装的docker无法启动,因为WSL2方式的ubuntu里面没有systemd。上述官方get-docker.sh安装的docker,dockerd进程是用ubuntu传统的init方式而非systemd启动的。
这个坑我是踩过的,在WSL2上按照Linux方式安装docker会失败,服务起不来的。
docker compose
Graylog运行需要三个镜像:
-
Graylog: graylog/graylog
-
MongoDB: mongo
-
Elasticsearch: Elasticsearch
这意味着我们需要拉取三个镜像,分别启动对应的容器,其间还涉及路径映射、端口映射等操作,烦死人。
还好我们有 docker compose ,它是一个用于定义和运行多个容器的工具,我们可以通过 yaml 来配置容器服务,使用一条命令拉起所有容器。
具体技术细节在这里就不多讨论,我主要记录如何配置一个有效的Graylog的 docker-compose.yaml 。
version: '2'
services:
# MongoDB: https://hub.docker.com/_/mongo/
mongodb:
image: mongo:4.2
volumes:
- /home/albusguo/graylog/volumes/mongo_data:/data/db
# Elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/7.10/docker.html
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
volumes:
- /home/albusguo/graylog/volumes/es_data:/usr/share/elasticsearch/data
environment:
- http.host=0.0.0.0
- transport.host=localhost
- network.host=0.0.0.0
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
mem_limit: 1g
# Graylog: https://hub.docker.com/r/graylog/graylog/
graylog:
image: graylog/graylog:4.3
volumes:
- /home/albusguo/graylog/volumes/graylog_data:/usr/share/graylog/data
entrypoint: /usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh
links:
- mongodb:mongo
- elasticsearch
restart: always
depends_on:
- mongodb
- elasticsearch
ports:
# Graylog web interface and REST API
- 9000:9000
# Syslog TCP
- 1514:1514
# Syslog UDP
- 1514:1514/udp
# GELF TCP
- 12201:12201
# GELF UDP
- 12201:12201/udp
这个文件的内容和 官方文档 提供的Demo不太一样,我主要做了几点修改:
-
直接把路径映射写死在文件里面,比如
/home/albusguo/graylog/volumes/graylog_data:/usr/share/graylog/data表示我主机上的/home/albusguo/graylog/volumes/graylog_data和Graylog容器内的/usr/share/graylog/data同步; -
删除了Graylog容器的环境变量。例如官方Demo里面配置了
GRAYLOG_PASSWORD_SECRET用于设置登录密码等,我们要采用配置文件的方式,因此这里没必要再写。
Step 1 运行
有了 docker-compose.yaml 之后,还需要做一些工作才可以成功把容器运行起来。
Graylog配置
在写 docker-compose.yaml 的时候提到,我在文件中删除了Graylog容器的环境变量,因为我们要通过配置文件的方式来传递这些参数。
Graylog的配置文件存储在 容器内 的 /usr/share/graylog/data/config/ 路径下,而这个路径的父路径 /usr/share/graylog/data 跟我们宿主上的 /home/albusguo/graylog/volumes/graylog_data 关联在一起,因此我们要预先在宿主上设置好配置文件,否则Graylog无法获取到正确的参数。
官方推荐的配置文件下载办法是:
mkdir -p ./graylog/config
cd ./graylog/config
wget https://raw.githubusercontent.com/Graylog2/graylog-docker/4.3/config/graylog.conf
wget https://raw.githubusercontent.com/Graylog2/graylog-docker/4.3/config/log4j2.xml
可以直接科学上网拿到这两份文件的内容,写到正确的位置上即可。
root@AlbusGuo-PC:/home/albusguo/graylog# ll /home/albusguo/graylog/volumes/graylog_data/config/
total 52
drwxrwxrwx 2 1100 1100 4096 Sep 25 12:14 ./
drwxrwxrwx 8 root root 4096 Sep 25 12:14 ../
-rw-rw-rw- 1 root root 35822 Sep 25 12:24 graylog.conf
-rw-rw-rw- 1 root root 1629 Sep 25 12:13 log4j2.xml
-rw-rw-rw- 1 1100 1100 36 Sep 25 12:14 node-id
口令设置
Graylog需要为 admin 账户设置登录口令,这要求我们在配置文件里写上口令明文和口令的 SHA256 值。
使用 pwgen 生成口令,位数一定要多一点,有些教程在这一步简单生成了十几位口令,而我使用的Graylog要求 64 位以上,在这里会翻车。
pwgen -N 1 -s 96
# 记录这个输出,记作 pwd
echo -n"Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1
# 输入刚才得到的 pwd,得到它的SHA256值
我们得到的这两个值,分别填到 graylog.conf 文件当中的 password_secret 字段和 root_password_sha2 字段,这样才可以使用 admin 登录Web服务。
路径权限
由于我们做了路径映射,就要使得容器有对应宿主路径的写权限。例如把主机上的 /home/albusguo/graylog/volumes/es_data 映射到 elastic-search 容器内的 /usr/share/elasticsearch/data 路径,那么这个容器就要有写 /home/albusguo/graylog/volumes/es_data 的权限,否则会因容器内部做的修改无法同步到主机上而产生错误。
一个比较简单的方法是 chmod -R 777 /home/albusguo/graylog/volumes/ ,开这个路径下的全部权限,也可以使用 a+w 的选项,总之这是一个需要注意的点。
运行
万事俱备,启动运行!
docker-compose up
# ...........
# graylog_1 | 2022-09-25 07:29:06,729 INFO : org.graylog2.bootstrap.ServerBootstrap - Graylog server up and running.
Step 2 配置输入流
配置
成功启动容器之后,可以通过 localhost:9000 访问到Graylog的web界面。
账号是 admin ,密码是 此前 生成并写入配置文件的明文。
进入Web界面,直接开始配置输入流。【System】——【Inputs】,选择一个输入流,如TCP文本数据:
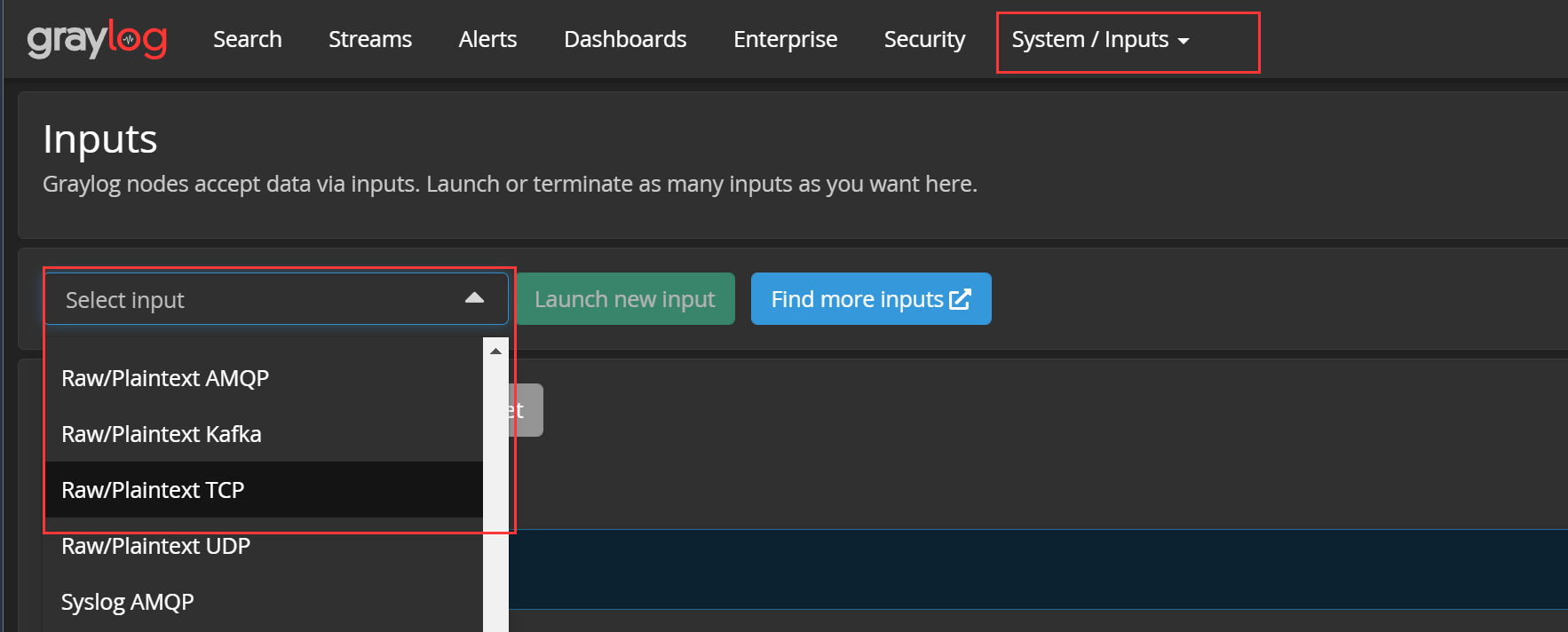
点击【Launch new input】启动该输入流,来到配置界面,我们主要关注两点:
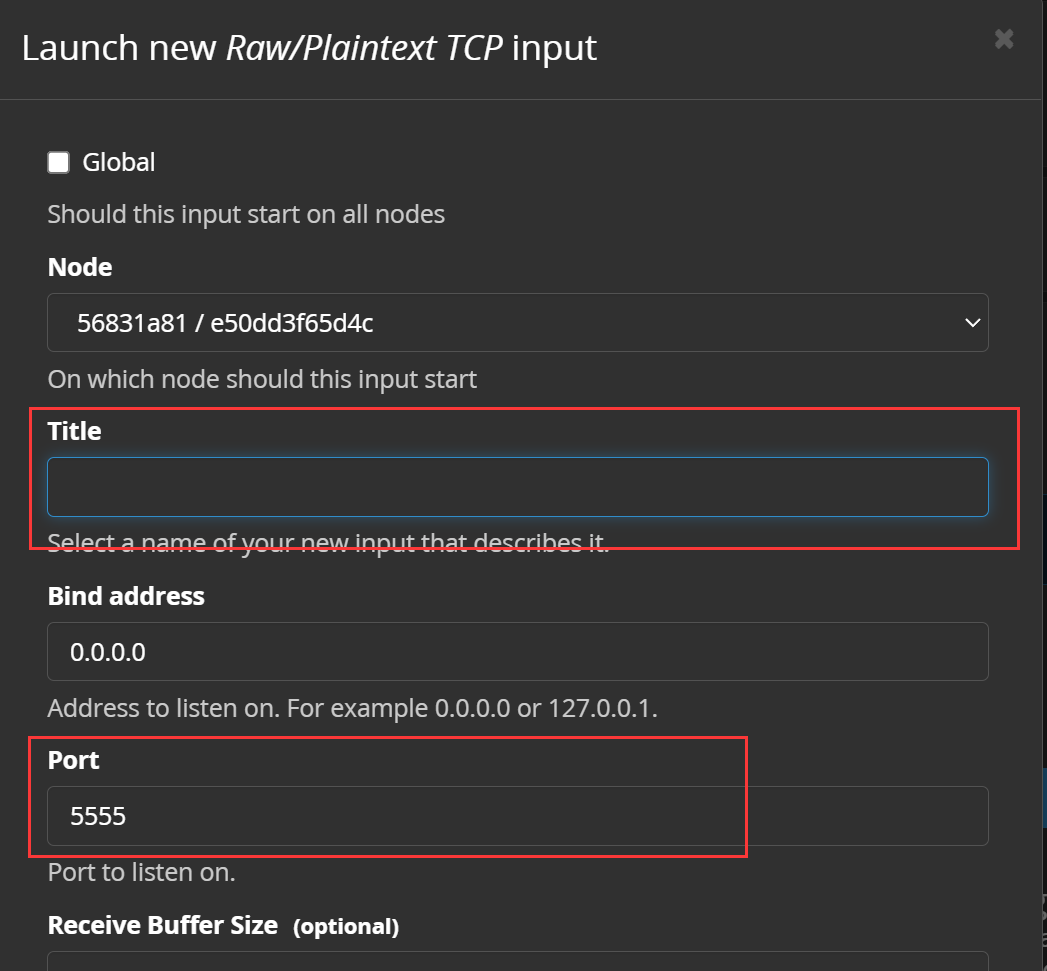
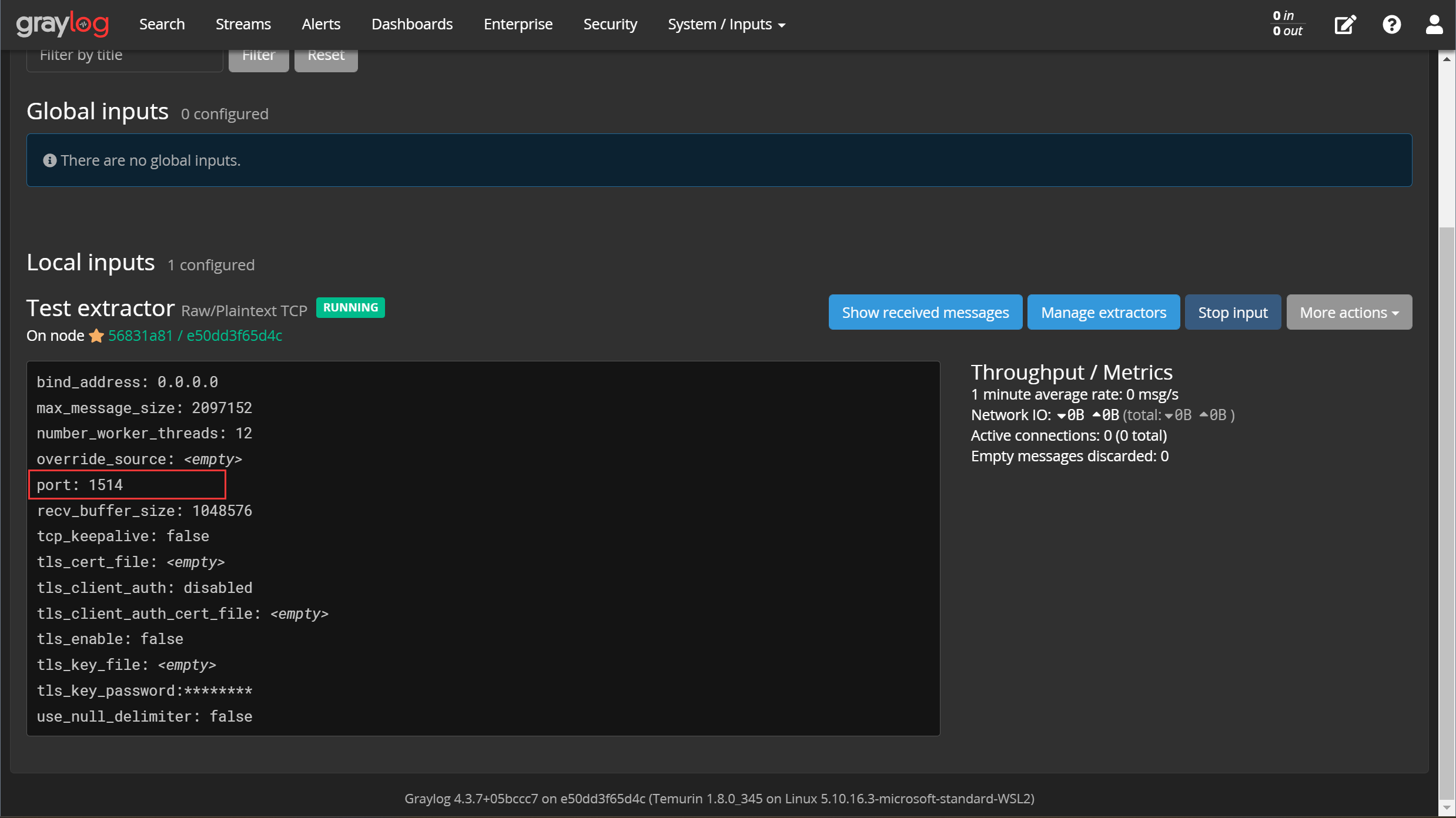
一定要注意这里的端口号,由于我们的Graylog运行在docker内,外界数据要通过主机端口转发到容器端口,这里的端口要选择此前配置过端口映射的端口。
还记得我们的 docker-compose.yaml 吗?在这个文件内为graylog容器配置了端口映射:
===== snip =====
ports:
# Graylog web interface and REST API
- 9000:9000
# Syslog TCP
- 1514:1514
# Syslog UDP
- 1514:1514/udp
# GELF TCP
- 12201:12201
# GELF UDP
- 12201:12201/udp
必须选择这里有的端口,否则我们的数据无法到达容器。
以TCP端口 1514 为例,只要在input配置界面写上这个端口,滑到底端保存,就完成了一个输入流的配置:
检查
我们来检查一下这个输入流是否生效。
随便找一些数据,这里我以自己的一个小站点的日志为例:
cat log_example.log
...
20220924 13:06:36.291066 UTC 3863 DEBUG [handleError] [10.206.0.6:443--8.142.110.170:38452] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
20220924 13:06:41.610243 UTC 3863 DEBUG [handleError] [10.206.0.6:443--8.142.110.170:46002] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
20220924 13:06:43.722297 UTC 3863 DEBUG [handleError] [10.206.0.6:443--8.142.110.170:51386] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
20220924 13:06:46.300990 UTC 3863 DEBUG [handleError] [10.206.0.6:443--8.142.110.170:55796] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
20220924 14:55:20.584554 UTC 3863 DEBUG [handleError] [10.206.0.6:80--8.142.110.170:34386] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
20220924 14:59:44.488731 UTC 3863 DEBUG [handleError] [10.206.0.6:443--82.157.59.178:15274] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
20220924 15:00:31.891461 UTC 3864 ERROR error - MysqlConnection.cc:536
20220924 15:00:31.891501 UTC 3864 ERROR Error(2006) [HY000] "MySQL server has gone away" - MysqlConnection.cc:498
20220924 15:00:31.891508 UTC 3864 ERROR sql:select * from excerpts - MysqlConnection.cc:500
20220924 15:27:40.884592 UTC 3863 DEBUG [handleError] [10.206.0.6:443--167.248.133.119:34466] - SO_ERROR = 104 Connection reset by peer - TcpConnectionImpl.cc:930
我们使用 netcat 来把这些数据发送到graylog的端口上, 注意刚才配置的输入流端口是容器端口,而数据发送的端口是主机端口 ,如果你在端口映射阶段把两者的端口设置为不同,在这里就要花点时间理清它们的关系。
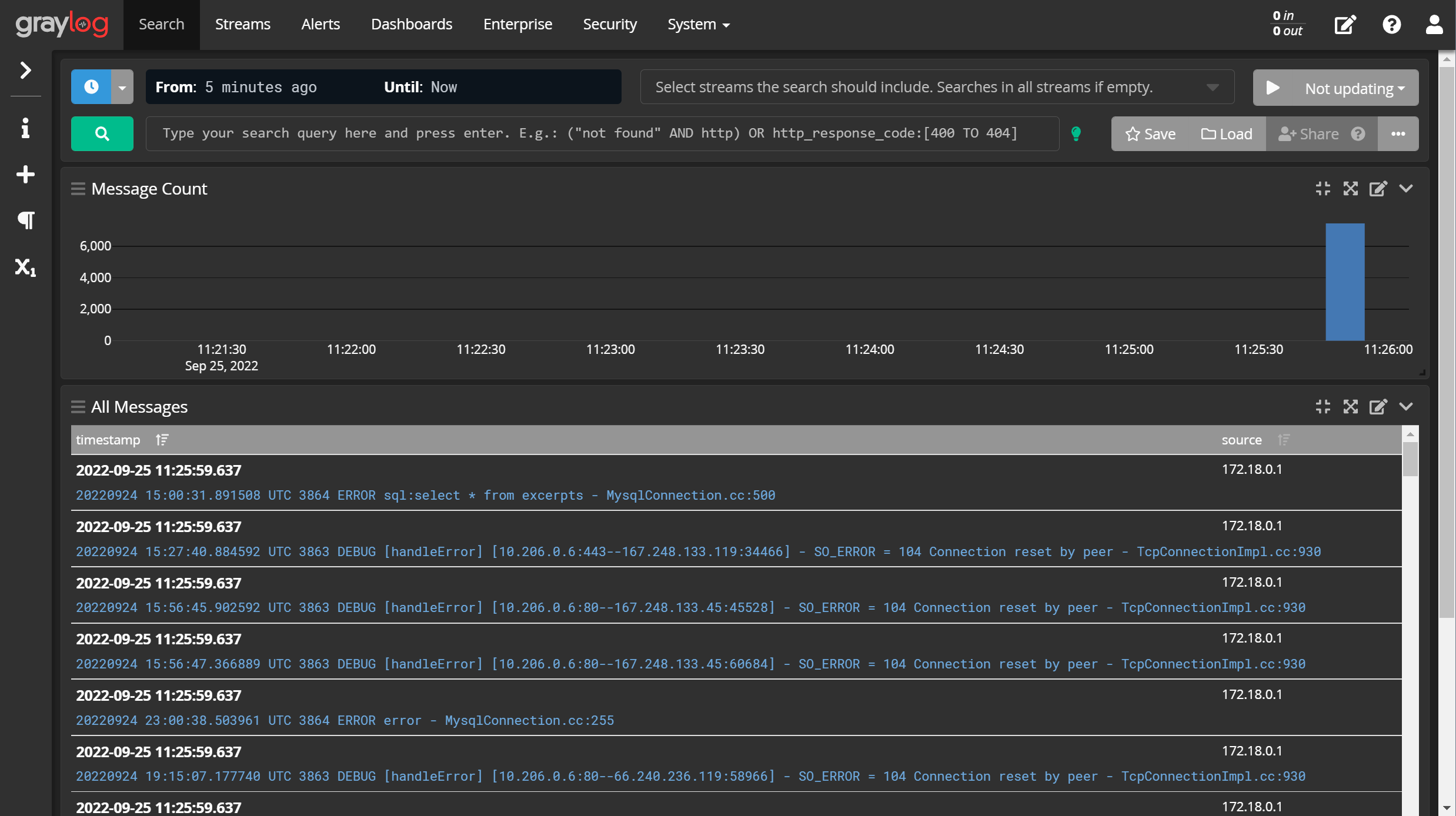
cat log_example.log | nc 127.0.0.1 1514
来到graylog的【Search】界面,看到刚才发送的日志数据,即说明输入流工作正常。
Step 3 配置提取器
extractor 提取器是从输入流当中提取字段的工具,这常见于需要对日志数据进行分析的场景,如网络连接日志,我们需要从日志当中提取访客IP。
不过这里还是以刚才的日志为例,注意到日志当中有一些日志形如:
20220924 15:00:31.891508 UTC 3864 ERROR sql:select * from excerpts - MysqlConnection.cc:500
似乎是执行SQL语句的记录,那么,我们的焦点就是被执行的SQL语句是什么,接下来配置提取器来把它从日志当中提取出来。
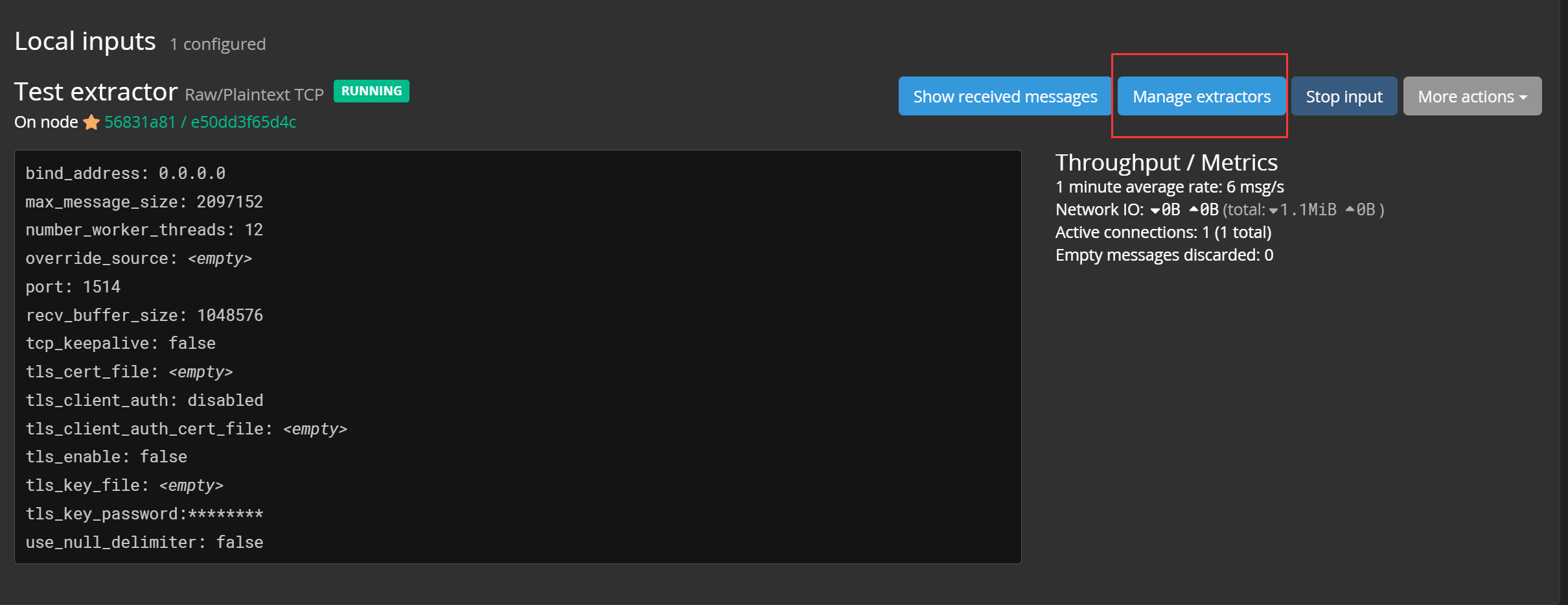
还是在配置输入流的界面,选择配置提取器:
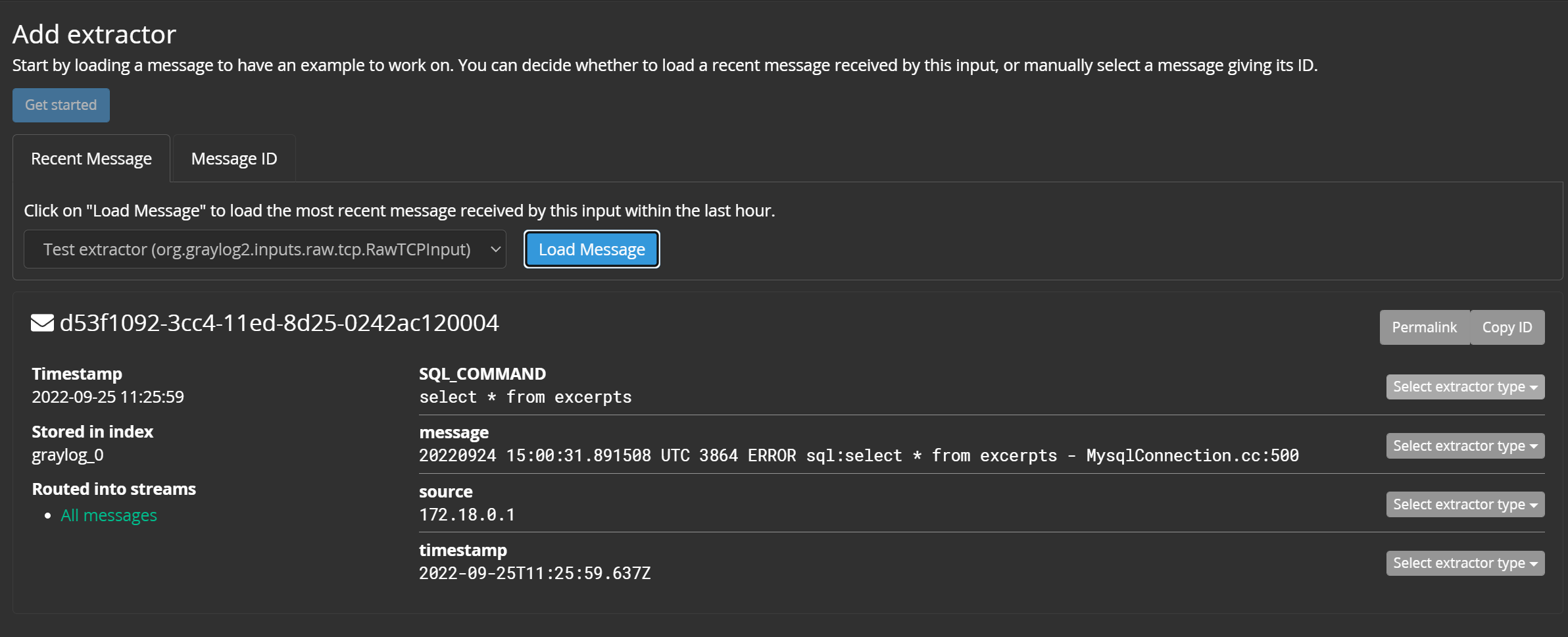
添加提取器,选中一条示例数据(Message ID可以从【Search】界面获取):
在示例数据上选择提取类型,最常见的是正则:
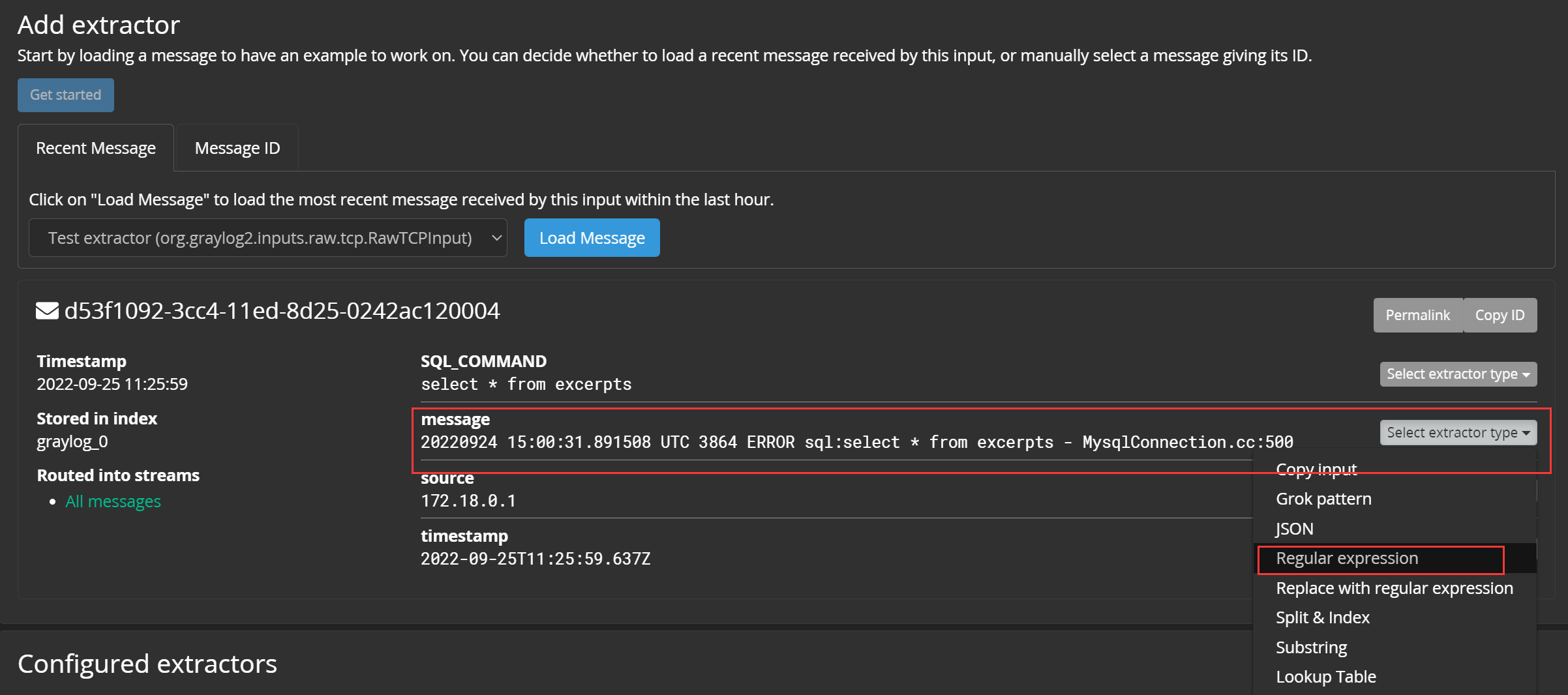
撰写适合于此类数据的正则,要提取的 目标字段用小括号括起来 ,并且要注意正则的普适性:
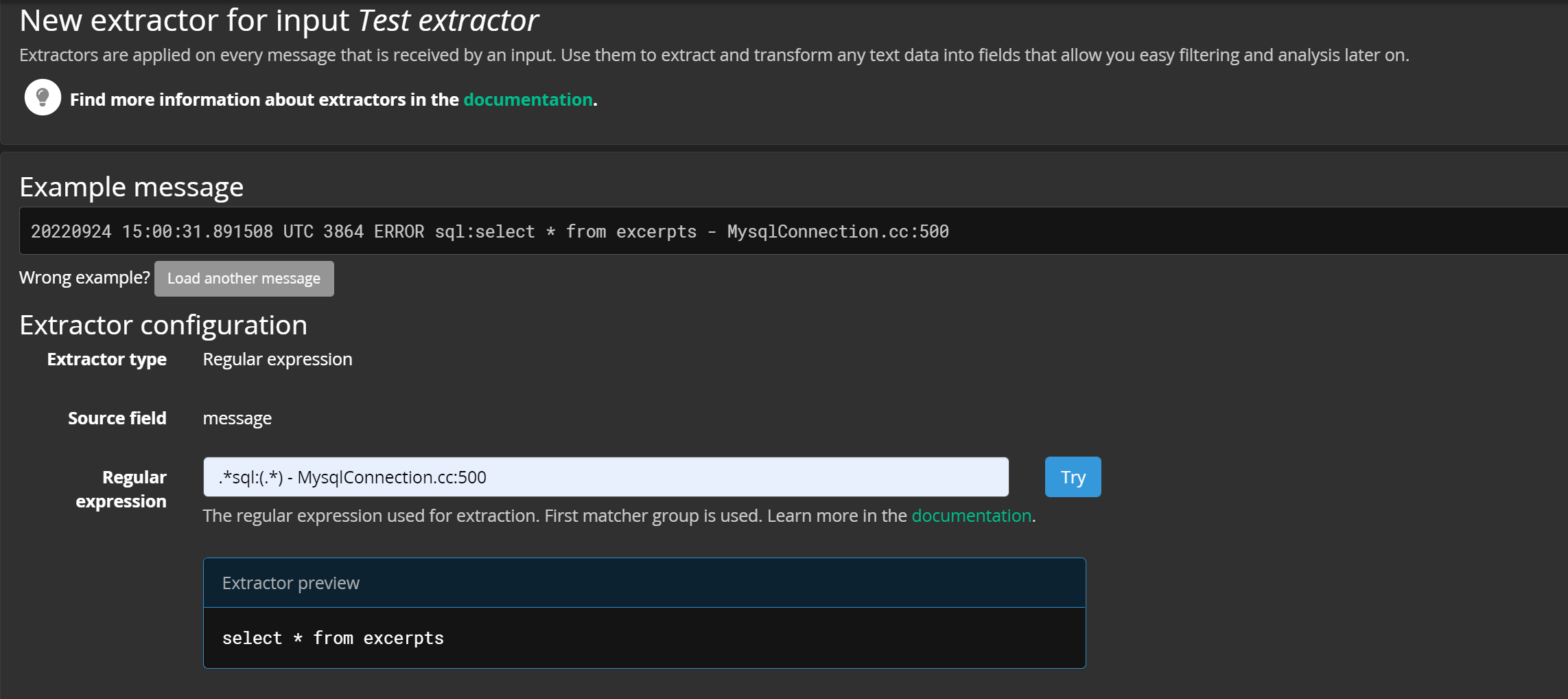
如果没有问题,就可以为提取出的字段命名,保存即可。
重新打入数据,再来到【Search】界面,点开一条日志,可以看到已经提取出了 SQL_COMMAND 字段(字段名是自己写的):
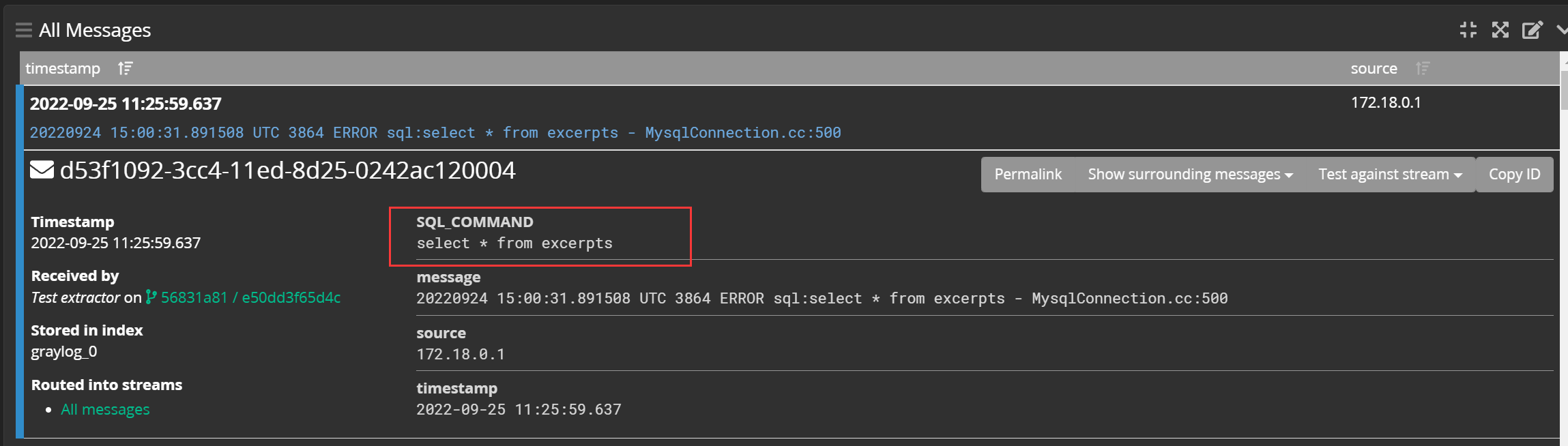
而其他的日志内容不符合我们刚才写的正则,那么它就不存在这个字段:
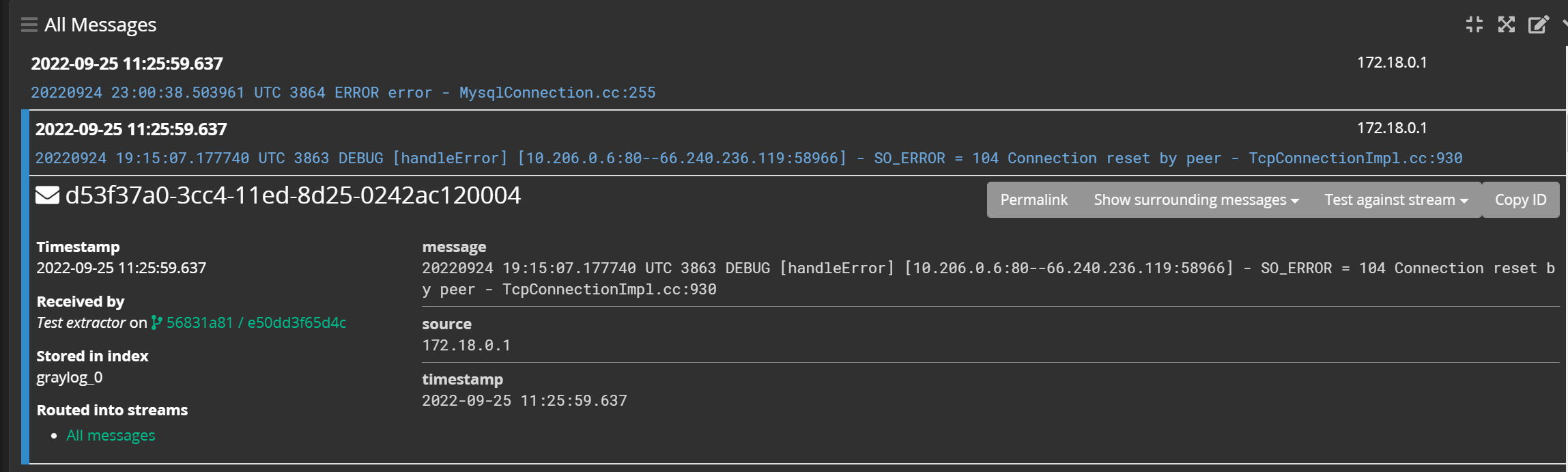
这个字段的有无,也可以作为我们对日志进行筛选的一个规则:
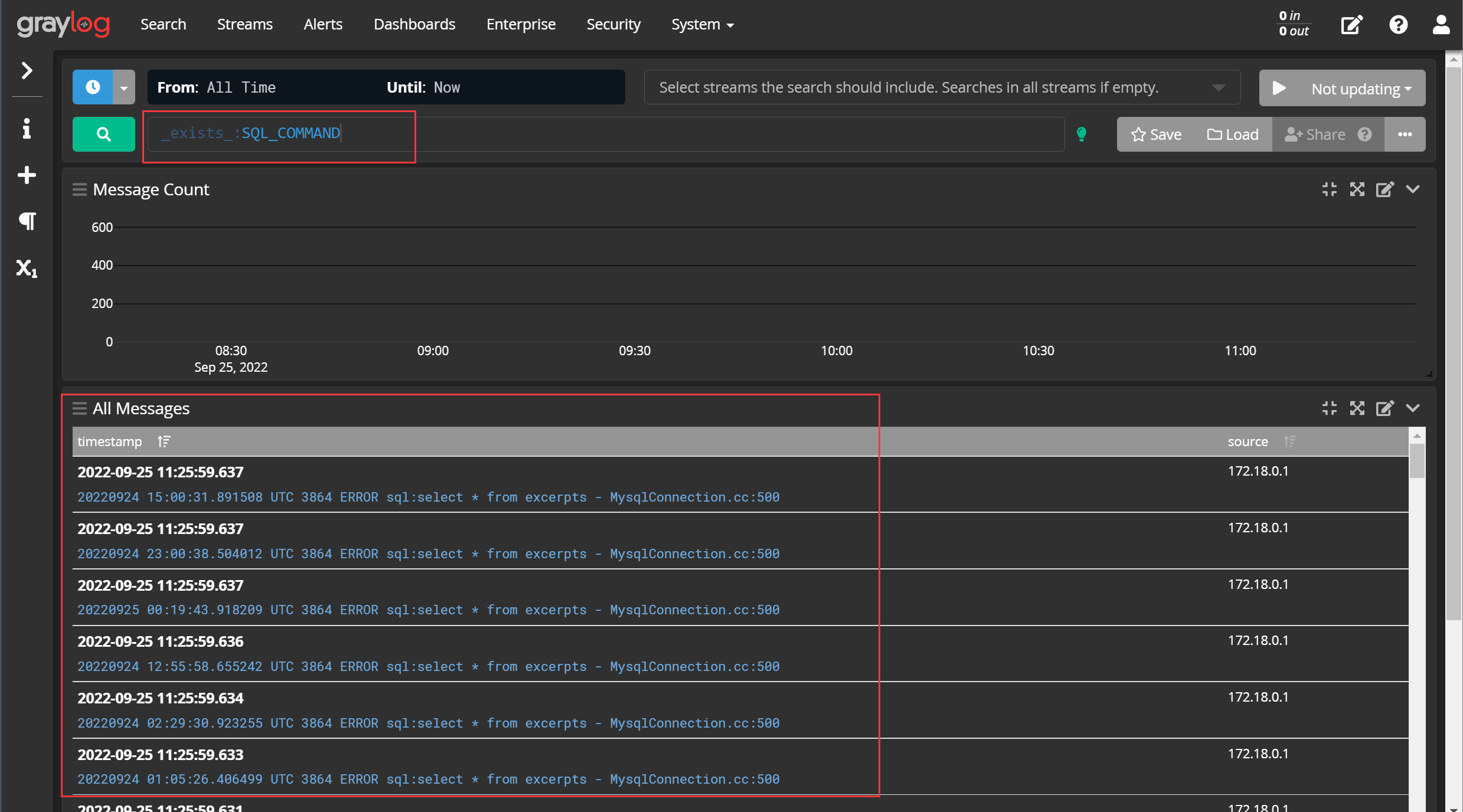
更多的筛选写法可以参考 官方文档 。
Step 4 事件和告警
除了筛选之外,Graylog还支持事件和告警的配置。
【Alerts】——【Event Definitions】,新增事件:
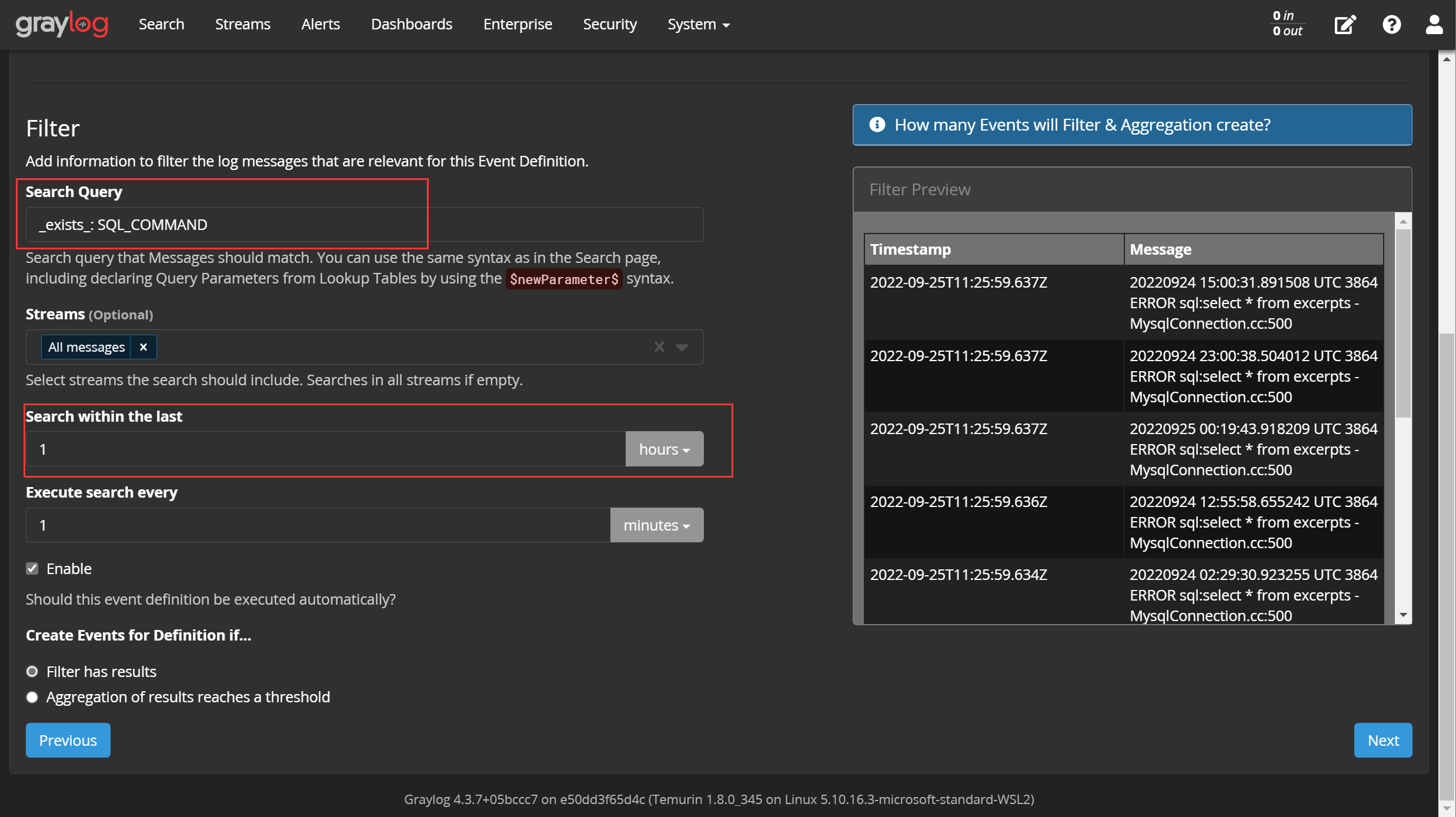
事件的核心是过滤器,我们要从日志中过滤出我们关注的事件,可以使用刚才使用过的 筛选语法 :
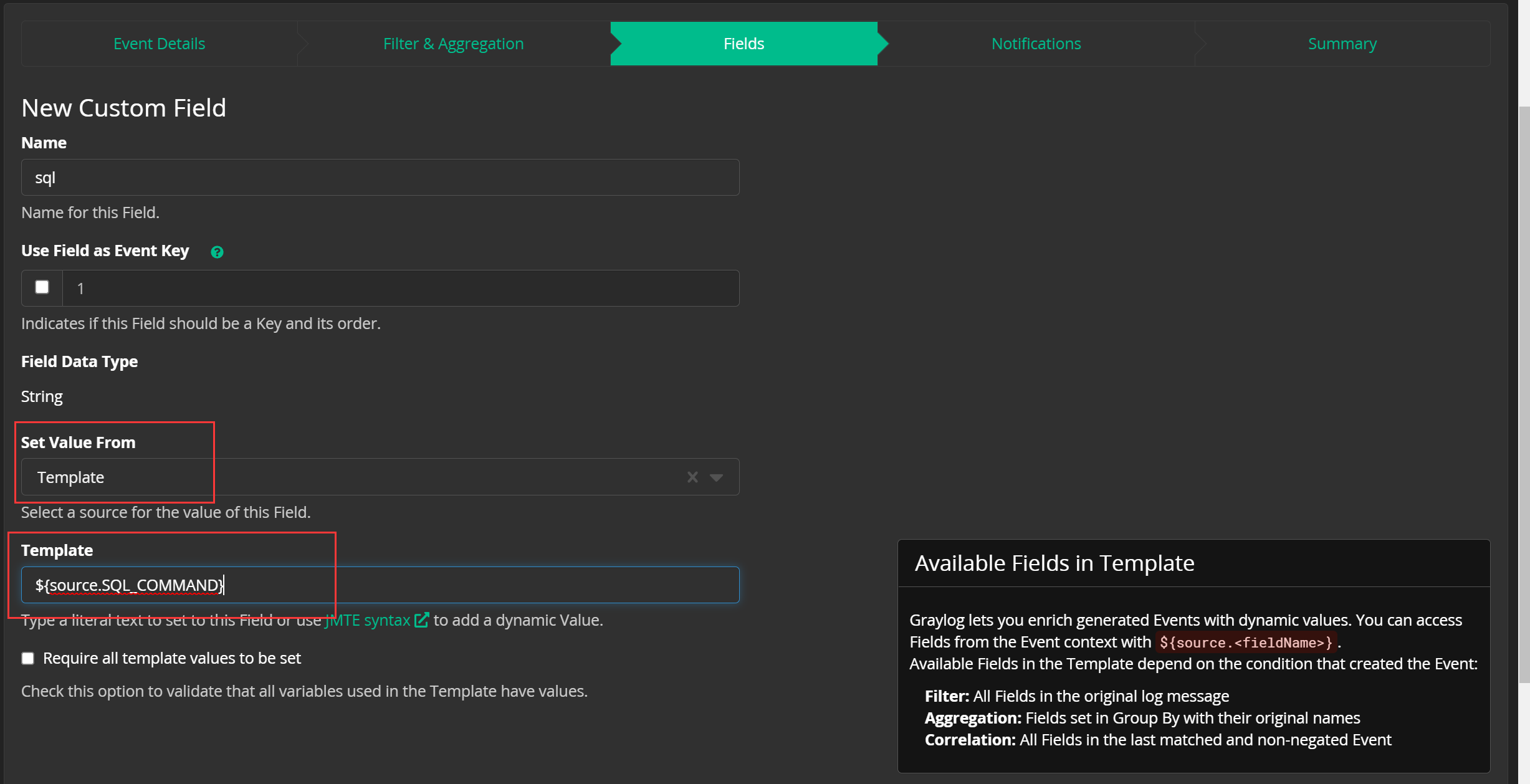
还可以从日志当中提取关键字段,以便我们对事件进行分析:
事件发生时,Graylog执行提醒动作,例如向指定邮箱发送邮件,在这里就不配置了。
整个事件的配置如下:
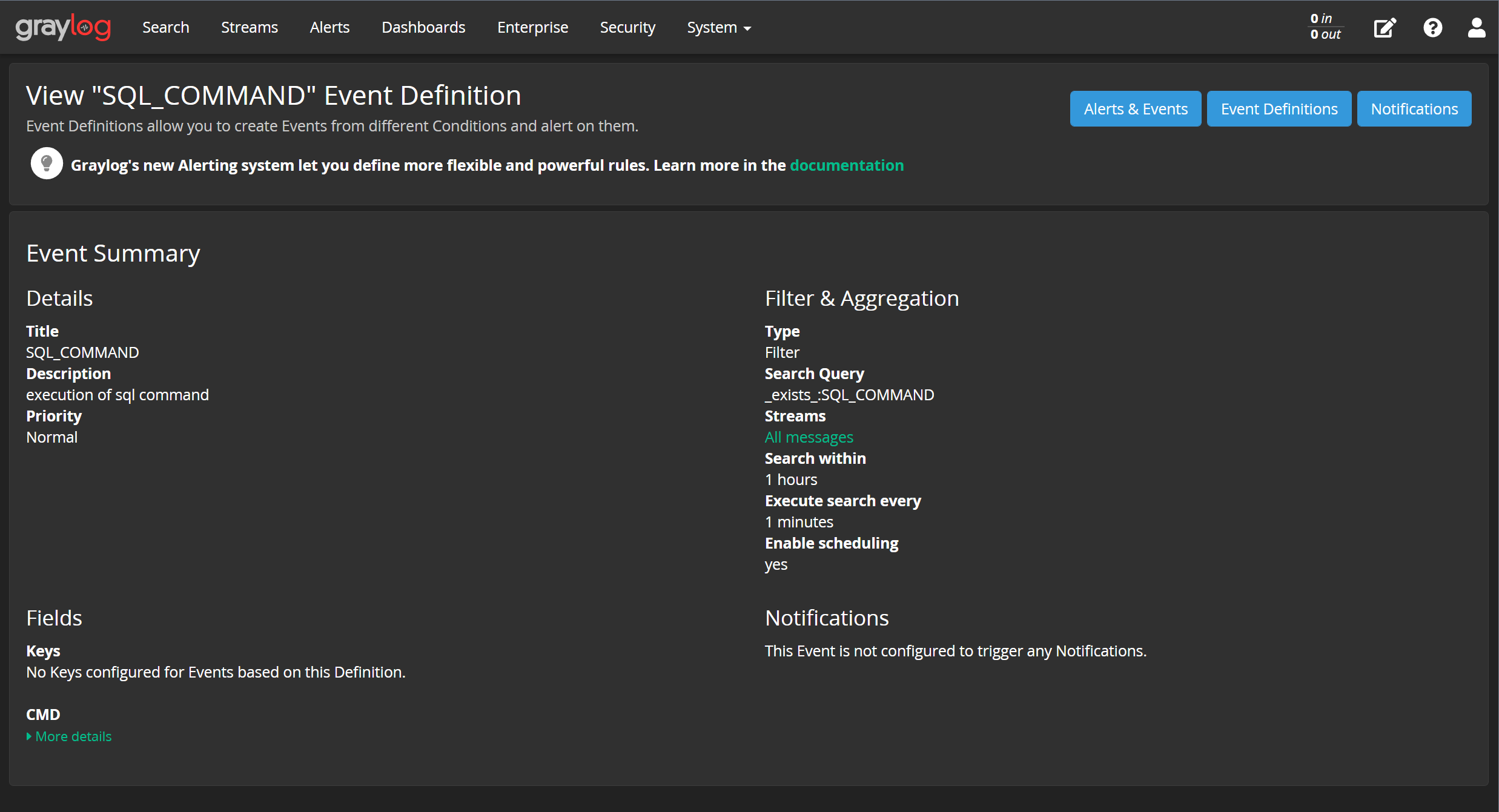
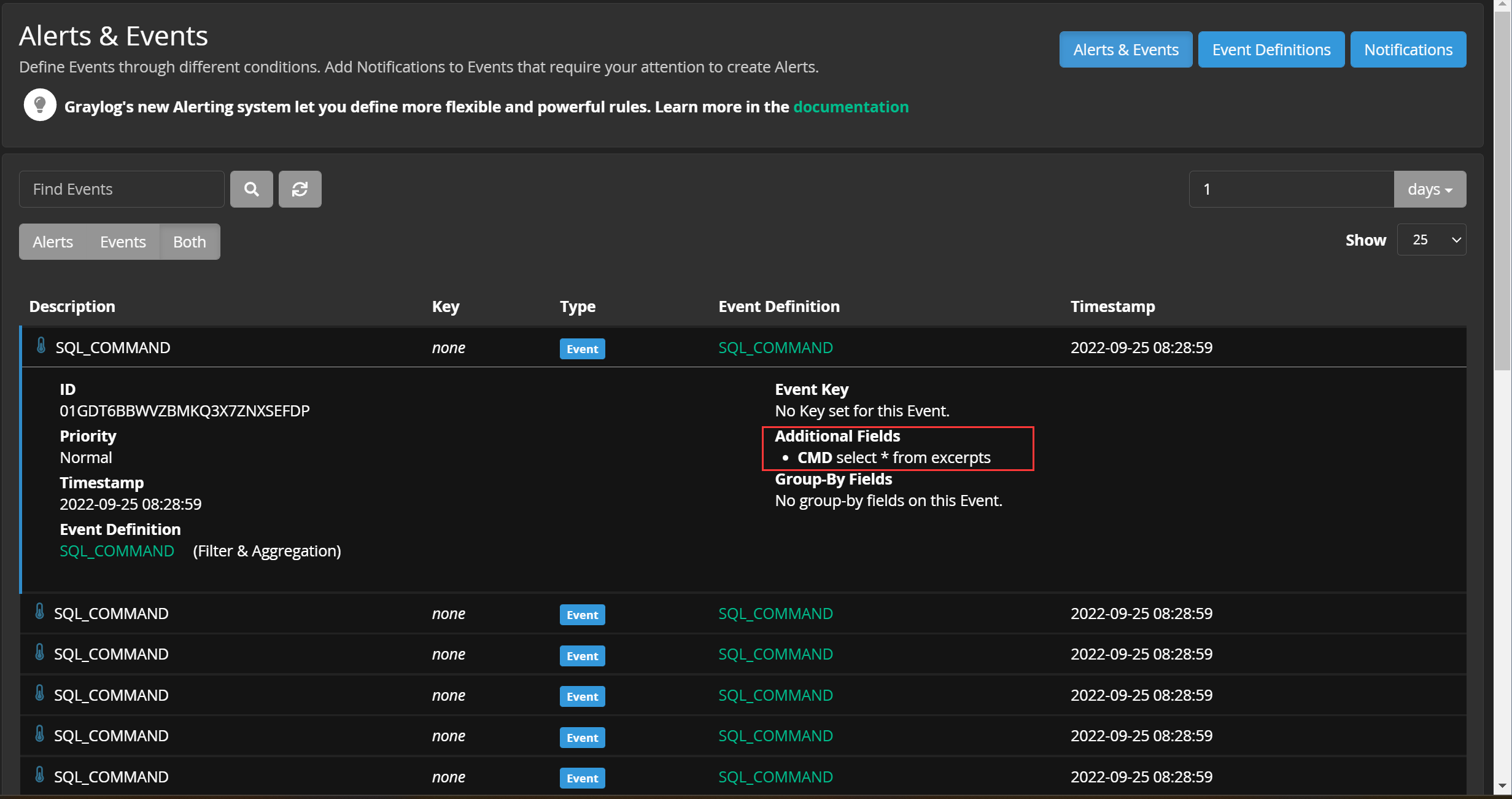
至此,可以从一大堆日志当中分析出我们想要的事件,并且事件当中包含了我们配置的额外字段:
Final 分析&小结
分析
简单使用过Graylog之后,我想对它的功能和意义做一点分析。
首先,乍一看很容易把提取器、筛选、事件混为一谈,尤其是三者都支持正则;但是,它们的定位是明确的:
-
提取器:从原始消息里面提取出可用字段,如果我们需要使用日志当中的某些内容,那么一定需要提取器;甚至,提取器得到的字段可以被筛选语句和事件所使用,因此它可以看成是日志分析的一个基础。
-
筛选:筛选和事件基本是一样的,但筛选的能力比较弱,我们可以从一大堆日志里面筛选出我们需要的日志,但筛选的结果并不能说明什么内容,甚至于我们拿个文本编辑器来筛都可以得到差不多的效果。
-
事件:事件是日志处理的结果,它不仅支持筛选,还支持聚合。我们在分析问题的时候通常关注事件而不是日志,我们要知道发生了什么,而不是所有的细节。
以一个场景来引发读者与我一起进行综合性思考:如何使用Graylog对常见的 暴力破解 进行告警?
自上往下看,我们关注的是 暴力破解 事件,因此这个事件是必然要定义的。事件的筛选比较简单,可以直接使用正则来匹配 登录失败 的日志,但并不是每条登录失败日志都应该触发这个事件,因此要设置聚合,比如匹配 20 条失败日志就触发暴力破解事件。
事件触发之后,我们最关心的问题应该是攻击者是谁,这个信息必须要从日志当中提取。因此,我们要对 登录失败 日志再配置一个提取器,来把日志当中的源IP提取出来。
至此,我们就把提取器、筛选和事件综合起来了。
不过还是有个小bug,事件聚合的时候只能考虑具有 相同源IP 的登录失败日志,不过这一点可能是Graylog的进阶用法,今天还没探索到这个地步。
小结
月末周日是非常短暂的,简单玩了玩Graylog,写了篇记录,就结束了短暂而愉快的一天。本文从docker安装开始,介绍了Graylog的配置、运行、输入流、提取器和事件,初心是把这些东西运用到我的工作中,提升问题定位的效率。目前来看,具备一定的实用性,至少界面会比notepad++友好许多,有机会投入实战检验一下效果。
参考资料
[1]“Get started with Docker remote containers on WSL 2,” Learn, Sep. 22, 2022. https://learn.microsoft.com/en-us/windows/wsl/tutorials/wsl-containers
[12]“docker wsl2启动不了_win10利用WSL2安装docker的2种方式_weixin_39786155的博客-CSDN博客,” Blog, https://blog.csdn.net/weixin_39786155/article/details/110363154
[3]“Search query language,” Docs, https://docs.graylog.org/docs/query-language
[4]“Docker,” Docs, https://docs.graylog.org/docs/docker