自后端篇之后,各方面进度逐渐加快,以至于基本没有时间慢慢跟进记录了。
目前站点已经上线 https://119.45.233.104/ ,直接访问会显示证书不安全,忽略安全警告即可(证书完全合法,产生警告是因为证书是跟域名绑定的)。其实域名也已经搞定了,但是解析到国内IP的域名需要备案,过一阵子再说吧~
本篇主要是进行一个收尾总结工作,除非之后有较大改动,否则对于读书摘抄站点的叙述就到此为止了,总共三篇,事不过三嘛!
0x00 后端开发环境转移
后端开发环境已由上一篇所述的 Windows+VisualStudio 改换到 CentOS 7+VSCode远程开发 ,引发这个决定的因素主要有几点:
-
VisualStudio 对 CMake 项目不太友好,自动添加若干编译选项,还有各种Cache,每次编译都要面临各种依赖问题,很烦;
-
VCPKG 安装的依赖存在大大小小的问题,折腾了若干次环境变量,我意识到根本没必要在这方面继续浪费时间了;
-
导火索:根页面的控制器
IndexCtrl都已经写完了,在尝试联通MySQL的时候报错找不到数据库,直接炸裂,怒而弃坑。
还是依照 Drogon WiKi 在 CentOS 7 上配好了环境,没出现任何问题,不得不服气。
在 Windows/MacOS 上都可以安装VSCode,下载 RemoteDevelopment 插件即可配置远程开发,网上教程很多,此处不表。
0x01 前端引入VUE
在前后端结合的时候,出现了一个超级难受的情况:Drogon自带的页面渲染机制CSP出现了中文乱码的问题。这个问题不是Drogon的问题,而应该是我在配置编码上存在一些纰漏,但是 我不想承认我的问题 我不想花时间去调试这一非主流的技术,而且我一直担心我的小破服务器吃不消后端渲染,因此决定尝试一下此前从未搞过的前端渲染。
前后端渲染的区别主要在于最终页面是在哪里生成的。后端渲染是在服务端生成我们最终看到的页面,而前端渲染主要是由浏览器生成我们最终看到的页面。前端渲染的好处是前后端连通的时候只需要传输一些简单的数据即可,而且由于“在前端渲染”这一特性,实现一些异步功能的时候更加简单(如分段加载)。
VUE 是一个前端渲染框架,只需按照给定的语法,提供特定的数据(例如使用Ajax从服务端请求),就可以实现前端渲染。
现有的VUE项目规模都比较大,用到了一些高级特性,如单文件组件等;我的读书摘抄站点满打满算一共三四个页面,不怎么存在组件复用等情况,因此我直接将每个文件都绑定一个VUE APP,各自实现其功能。对于VUE来说,主要只用到它的实时渲染的特性而已。
前端引入VUE之后,交互就变得比较简单。目前还没有实现分段加载的功能,因此直接在页面加载的时候从后端获取所有数据。在VUE中定义一个 fetchData() 的方法,其中使用 axios 从后端请求数据,然后更新到实例的 data 上;这个方法在 mounted() 的时候被调用。需要注意,在 fetchData() 里面使用的 this 指向的不是组件实例,要从外部传入实例才行。
const app = Vue.createApp({
// ==== 略 ====
methods: {
// ==== 略 ====
fetchData(vueThis) {
axios
.get('/index')
.then(function (response) {
var respJSON = JSON.parse(JSON.stringify(response.data));
vueThis.login = respJSON["login"];
vueThis.cards = respJSON["cards"];
vueThis.totalBooks = respJSON["totalBooks"];
})
.catch(function (error) {
console.log(error);
});
}
},
mounted() {
let vueThis = this;
this.fetchData(vueThis);
}
}).mount('#app')
0x02 交互逻辑设计
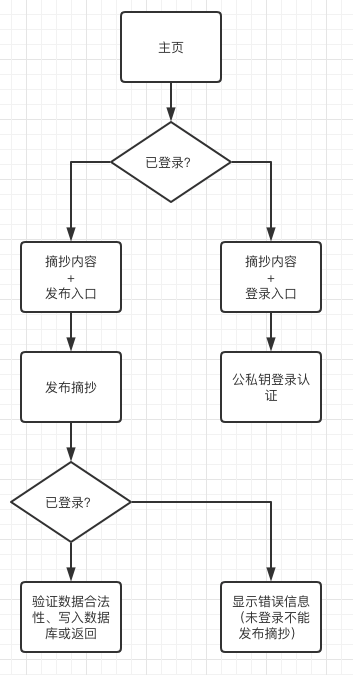
整个站点的交互逻辑比较简单,无论是否登录都能查看我的摘抄内容。登录的作用目前仅限于发布摘抄(将来有多人使用该站点的时候可以正式加入用户功能)。
个人认为登录认证的模块做得还不错,实际上也是本站工作量的集中体现,后续详谈。
0x03 登录认证
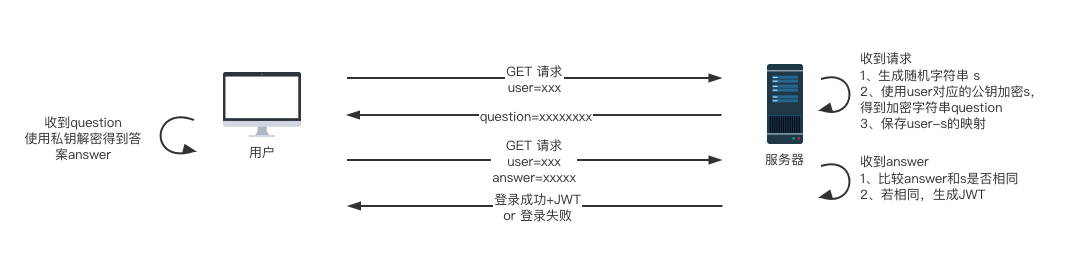
本站登录认证机制是 公私钥认证 ,实现思路如下:
-
用户向服务器发起登录请求,携带参数
user=xxx; -
服务器根据用户名找到该用户的公钥(已经预先保存好),生成随机字符串
s,保存user-s这一映射关系;用公钥加密s得到加密后的字符串question,该加密串还需要使用Base64编码,然后传输到前端; -
前端脚本得到
question,使用用户输入到文本框的私钥对其进行解密,得到解密后的字符串answer,返回给服务器,参数为user=xxx;answer=xxxxx; -
服务端收到
answer,将其与s进行对比;-
登录成功:服务端生成JWT(Json Web Token),返回前端告知登录成功;
-
登录失败:返回前端告知登录失败。
-
-
登录成功之后前端会获取一个JWT,将其保存到cookie;
-
此后所有请求都会带上JWT,后端获取JWT进行验证即可判断用户的登录状态。
这个登录机制的安全分析如下:
-
每个用户对应的公私钥都是唯一的,使用用户公钥加密的随机串,只有拥有私钥的用户才能解密,因此,用户的身份可以得到确认;
-
用户私钥只用于浏览器端解密,不传输到网络上,因此私钥私密性可以保证;
-
登录成功之后获取的JWT,标准的实现办法应该是将其存放到 local storage ,但这里直接存到cookie,主要是基于实现难度进行的选择;
-
cookie需要针对CSRF攻击进行一系列加固(HTTP only等);
简单记录一下这个登录机制的实现方案:
-
后台C++使用openssl实现的RSA公钥加密,支持的公钥格式应以
BEGIN PUBLIC KEY开头; -
#include <drogon/utils/Utilities.h>并使用utils::base64Encode这个Drogon API来进行Base64编码; -
引入 CPP-JWT 这个第三方库来实现JWT的生成和解析;
-
前端使用 JSEncrypt 来实现RSA私钥解密;
-
JWT和cookie都设置过期时间(暂定1天)。
这个方案其实进行了一些取舍:
-
JWT存到cookie,是一种妥协。标准的做法是实现 本地存储 ,然后每次进行请求时都从本地获取JWT并放入请求头(如axios设置拦截器)。但是,我的页面中并不是所有的请求都是由我控制的,即并不是所有请求都是由Ajax代码发起的:当直接使用浏览器访问某个页面时发起的GET请求就可能不带JWT,就失去了一致性;将JWT放到cookie中可以解决这一问题,带来的CSRF等安全性问题则需要其他办法进行加固。
-
急于上线使用,没有手撸加密算法,因此学到的东西不多。 😢
0x04 数据库
数据库也是可能出现安全问题的一个点,当初构思时考虑了 加密存储 ,后来觉得这种私密性很弱的数据库没有什么加密的必要(本来就是希望所有人都能看到我摘抄的内容),因此放弃了加密的想法。
数据库方面有几个要点:
-
使用了Drogon的 ORM模型 ,即,Drogon提供的将数据库操作抽象出来的一套方法;使用了ORM之后,我的操作就只有
mapper.insert()和mapper.findAll()了,后续要加功能的话再研究条件查询; -
数据库里面的
bookName和excerpt字段是非空的,即书籍名称和摘抄内容是非空的(不然还叫什么摘抄),因此在收到数据的时候要进行检查(前端也检查了一遍,但众所周知前端检查没啥用); -
防SQL注入!防SQL注入!防SQL注入! 这一点被ORM模型承包了,很提升幸福感;最初的方案是自己构造SQL,C++字符串转义什么的,比PHP还原始,比较痛苦。
-
灾备。考虑过若干方案,比如将mysql文件同步到OneDrive啥的,最后实现的办法是每天定时做一次全量备份,用
mysqldump把数据库弄出来,把数据 加密压缩 然后自动push到Gitee上。更加理想的方案是全量备份 +binlog增量备份,但是考虑到实现起来多一些步骤、而且我的数据库很小、就没有使用这个方案。
0x05 页面修修补补
前端页面CSS也是出了一些问题的,我把几个比较重要(但不一定困难)的修补在这里记录一下:
-
.content-wrapper类要添加height: 112.5px;属性,不然在FireFox和Safari浏览器下面排版会错乱,具体表现为overflow: hidden不起作用,被子元素撑开); -
.card类要添加white-space: pre-wrap;属性,不然换行会变成空格;读书摘抄没有换行简直是噩梦。这里不得不说一句Drogon的ORM做得很不错,把前端文本框传来的换行符忠实地存入数据库中了,省却一大堆事;
0x06 内容在线修改
2022-03-09加
原先就有的一个想法,希望在登录状态下能对浏览的卡片进行在线修改(例如心血来潮地添加一些评论或者纠正一下当初录入的错别字等等)。
这块功能在最初编写卡片代码的时候就预留出来了,按钮使用的是Bootstrap提供的三个图标,分别表示“开始编辑”、“保存编辑”、“取消编辑”。
把它们各自的功能简单叙述一下。
开始编辑:
-
点击“开始编辑”,出现“保存编辑”和“取消编辑”按钮;
-
获取原卡片数据,即把原本的书籍名称、摘抄内容、文章日期等内容都保存到全局变量里面,以便后续取消编辑的时候把数据恢复;
-
替换卡片元素,即把原本的
<h4>、<div>等标签替换为可编辑的输入框,这一点跟发布内容的时候是一样的,摘抄和评论用的是textarea而书籍名称等用的是input。这一步的做法用到了jQuery的$(obj).before()和$(obj).remove()这两个操作,分别是添加元素和删除元素。
Tips:要对添加的
input和textarea添加onclick事件,然后使用event.stopPropagation()来阻止冒泡,不然点击文本框的时候会触发卡片的回弹。
取消编辑:
-
与“开始编辑”的逻辑相反,点击后把文本框换回
<h4>、<div>等标签,并把保存在全局变量中的原数值复原回去; -
恢复元素这一系列操作要抽出来形成一个单独的函数,在卡片回弹的时候也要执行这个函数。
保存编辑:
-
获取文本框中的数值,然后用axois发送给后端;
-
Drogon使用
mapper.update(singleRow)来更新数据库; -
如果后端操作成功,则编辑保存完毕,更新全局变量,然后把卡片复原为只读形式;
-
如果后端操作失败,
alert()报错消息(本来应该自己做一个消息窗体以改善体验,但是有点懒,直接Alert了)。
在线更新功能的实现使整个站点的成熟度得到了飞跃,至此它已经跟一个在线记事本一样了。我可以自由地添加内容、修改内容,且每天都有数据库的备份,基本上完成了最初预想的功能。
0x07 图片分享
写于2022-06-09
时隔三月,重新搞起了读书摘抄站点~ 🤔
这次添加的是最初规划时就考虑到的分享功能,之前一直没有实现主要是因为懒,且觉得这个自娱自乐的站点貌似不太需要分享功能;最近想跟朋友分享我摘抄的一些很好的片段时,总得自己手动截图,比较难受;更有甚者,一些比较长的片段没法一次性截取完全,于是萌生出把分享功能完成的想法。
一直以来比较心水一键生成图片的那种功能,这次的开发就以图片分享为目标。
图片分享的基本原理:使用HTML canvas 绘制矢量图,之后可以选择使用 canvas.toDataURL 生成图片URL并生成 img 图片,或对 canvas 进行其他操作(如复制到剪贴板)。
图片分享的关键步骤是如何将要分享的内容绘制到 canvas 上,这一步有成熟的第三方工具 html2canvas ,可以自动解析DOM元素并生成图片,受到网上各教程的广泛使用。不过,经过我的测试,这个工具在绘制我的摘抄时会丢失一些样式,而且还得去调试它的各种参数,属于自讨苦吃,大可不必。
重新思考之后,我认为我的需求比较简单:只是将要分享的 文字内容 转换成图片而已,没有多少麻烦的步骤,因此决定手撸 canvas 。
生成分享图片的整体流程非常简单:
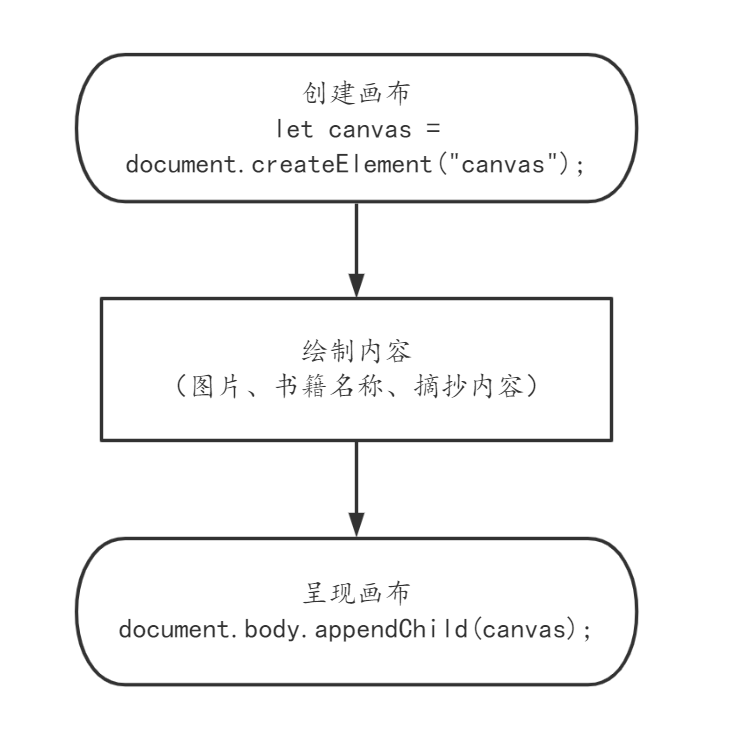
画布长宽根据屏幕大小而改变,但始终保持一个固定的比例:
let width = $(window).width() * 0.6;
let height = $(window).height() * 0.9;
画布的内容组织结构也很简单,只有三个部分:

使用 let ctx = canvas.getContext("2d"); 得到画布主体,之后获取目标内容进行绘制。
-
头部图片,设置好宽高,然后
ctx.drawImage(img, 0, 0, width, imgHeight);。 -
文字部分,要先绘制一个矩形背景,否则文字没有底色:
ctx.fillStyle = "#ffffff"; ctx.fillRect(0, height * 0.3, width, height); -
使用jQuery提取要分享的内容(通过DOM树获取书籍名称和摘抄内容的相应节点),分别在各自的位置上绘制字符串。
// 绘制文字 ctx.fillStyle = "#000000"; let opt = { 'headerHeight': 0.08 * height, 'leftPadding': 16, 'rightPadding': 5, 'bottomPadding': 16, 'textHeight': 0.6 * height, 'textWidth': width, 'maxFontSize': 20 } // 书籍名称 let fontSize = opt.headerHeight; fontSize = Math.min(fontSize, 24); ctx.font = fontSize.toString() + 'px ' + 'Long Cang'; ctx.fillText(bName.text(), opt.leftPadding, imgHeight + opt.headerHeight * 0.7); // 摘抄内容 let text = $(exp).text(); let realTextWidth = opt.textWidth - opt.leftPadding - opt.rightPadding; let realTextHeight = opt.textHeight - opt.bottomPadding; fontSize = Math.floor(Math.sqrt(Math.floor((realTextHeight * realTextWidth) / (2 * text.length)))); fontSize = Math.min(fontSize, opt.maxFontSize); ctx.font = fontSize.toString() + 'px ' + 'Noto Serif SC'; let cols = Math.floor((realTextWidth) / fontSize); let rows = Math.ceil(text.length / cols); for (let i = 0; i < rows; i++) { // 注意 substring 和 substr 两个不同API的区别 ctx.fillText( text.substr(i * cols, cols), opt.leftPadding, imgHeight + opt.headerHeight + fontSize * 2 * (i + 1) ); }
这里为了使得大段文字能够写入到一个固定高度的区域中,需要对 字体大小 进行一些数学上的计算。
已知待写入的字符串为 text ,画布文字部分宽度为 realTextWidth ,高度为 realTextHeight ,令字体大小为 fontSize ,则
$$ \text{列数 }col = \frac{realTextWidth}{fontSize} $$
$$ \text{行数 }row = \frac{text.length}{col} $$
令行高为两倍字体大小,即
$$ lineHeight = 2 \times fontSize $$
那么文字部分总共需要占据的高度就有
$$ row \times lineHeight = \frac {text.length \times fontSize}{realTextWidth} \times fontSize \times 2 $$
它不能超过画布提供的高度,否则会溢出,也就是需要满足
$$ \frac {text.length \times fontSize}{realTextWidth} \times fontSize \times 2 \leq realTextHeight $$
$$ \text{解得 }fontSize \leq \sqrt{\frac{realTextHeight \times readTextWidth}{2 \times text.length}} $$
这就是字体大小的要求。满足这一大小要求的字体才能将一个片段完整地写入画布中。
另一个 需要注意的地方是, canvas 写入文字时不能自动换行,超出画布的部分即不可见。为了实现 文字换行 的效果,需要手动对原始字符串进行切分,每一次只写入原始字符串的一部分(实际上就是写入列数 col 个字符),移动至下一行,再继续写入,这就是上方代码中的最后一个 for 循环所做的事情。
完成以上几点之后,能够绘制出一张很不错的分享图了:

最后,添加一个按钮,用于将这张图片一键保存到剪贴板。这里给出两篇重要参考, 第一篇 教会我们如何把 canvas 转化为可以写入剪贴板中的数据; 第二篇 介绍了浏览器的 navigator.clipboard.write 接口的用法,据此,可以实现一键复制图片的功能。
0x08 To Do
本文的叙述相比之前的两篇简单很多,因为内容实在太多了,详写不来 😢
整个站点还有一些地方是可以改进的:
-
分段加载!每次只加载一部分记录,滑动到最底部时再继续发起请求。这个功能需要前端发起请求时带上一些参数,后端数据库查询时也进行一些修改。
-
卡片出现的动画。试试VUE的transition标签,总之就是使卡片出现的时候丝滑一点。
-
大起始页。访问其他大佬的博客时觉得他们的首页美图很不错,滚动滚轮能触发全屏滚动呈现真正内容,可以考虑学习实现一下。
-
发布/展示页面对Markdown语法的支持,似乎用一些Javascript库就可实现。
-
……