2021-07-20,正式拉开了秋招备战的序幕。
我一直以来都深以为然的一个句子是,人一能之,己百之;人十能之,己千之。果能此道矣,虽愚必明,虽柔必强。 这个句子的意思是,如果你的学习能力比不上他人,那就花费百倍的精力去学,能够做到这一点的人,即使是一个愚者,也能够明了很多的知识。
1 C++引用和指针的区别
这个问题出现在昨天的面试中,在此予以学习和记录。
指针: 指针是一个变量,用于保存另一个变量的地址。指针需要使用 * 来进行解引用,以获取它指向的内存地址上的内容。
引用: 引用是一个 已经存在 的变量的别名,实际上,引用也是通过存储变量的地址来进行实现的。
两者的区别有如下几点:
-
初始化的方式不同。指针可以先声明,后赋值;引用必须在声明的同时进行初始化,因为它必须作为一个已经存在的变量的别名。
-
重复赋值。指针可以重复赋值(当然,const指针不行),而引用一旦声明,就不可以重复赋值。
-
内存占用。指针在栈上有其独立的内存空间(32bit机器就占用4字节),而引用与它的初始变量共享同一个空间,虽然它还是会花掉一部分栈空间。
-
是否为空。指针可以设置为NULL,而引用不行(基于第一点和第二点区别)。
-
间接引用。指针可以有多重嵌套,而引用不行。
In Pointers, int a = 10; int *p; int **q; //it is valid. p = &a; q = &p; // Whereas in references, int &p = a; int &&q = p; //it is reference to reference, so it is an error.
可以使用一句话来概括两者在实际使用中的规律:只在万不得已的时候使用指针。一般来说,引用会用在一个类的public接口中,而指针运用在其内部。
以下编辑于2021-07-25
传引用比传指针安全。 因为不存在空引用,并且引用一旦被初始化为指向一个对象,就不会被改变为另一个对象的引用;而指针可能被改变为另一个对象。
即使声明为常量指针 const Type* ,仍可能为空指针,并且可能产生野指针,所以还是不安全。
Reference
2 HTTPS流程
HTTPS的流程总结为如下步骤:
- 客户端向服务器发送自己支持的密码套件(cipher suit)和一个随机数
rc; - 服务端选择一套密码算法,连同自己的证书信息返回给客户端。在这里,服务端具体会将自己的公钥、数字证书、签名以及一个随机数
rs等信息发送给客户端; - 客户端接受服务端的证书之后,会根据
rc和rs生成一个随机的对称秘钥,同理,服务器此时也会生成相同的对称秘钥; - 双方加密通信。
以下于2021-07-24重编辑
还有一种对HTTPS流程的描述是:
- 客户端向服务器发送自己支持的密码套件(cipher suit);
- 服务端选择一套密码算法,连同自己的证书信息返回给客户端。在这里,服务端具体会将自己的公钥、数字证书、签名等信息发送给客户端;
- 客户端接受服务端的证书之后,会生成一个随机的对称秘钥,用服务端的公钥加密后发送给服务端;服务端收到消息之后可以解密得到对称秘钥;
- 双方加密通信。
实际上,这两种描述所不同的地方仅在于一个关键的步骤:密钥交换。
在第一种描述中,表现的是名为 DHE(Diffie-Hellman Exchange) 的密钥交换方式,而第二种描述中,表现的是名为 RSA密钥交换 的方式。第二种描述的实现方法法非常简单,但假如服务端的私钥被破解,将可以解密此前截取的所有流量,即这种办法不具备 前向安全 性。
Reference
[1] 让面试官膜拜你的HTTPS运行流程(超详细) - 知乎 (zhihu.com)
[2] HTTPS原理和通信流程 - 知乎 (zhihu.com)
[3] 石瑞生.大数据安全CH02-03-安全基础知识.2020年秋季学期.BUPT
昨天工作累爆,没有学习,今天休息,补上~
3 死锁
昨天遇到的面试题,答得还算可以,但是有一些点还是忘了。死锁也是网上各个面经的常客了,稍作梳理,不亏。
3.1 定义
操作系统中往往有多个进程在并发执行,而所谓死锁,是指多个进程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。
3.2 死锁产生的原因和必要条件
(1)系统资源的竞争
通常系统中拥有的不可剥夺资源,数量不足以满足多个进程运行的需要。若进程在运行中因为对不可剥夺资源的竞争而陷入僵局,就可能产生死锁。对可剥夺资源的竞争是不会引起死锁的。
(2)进程的推进顺序非法
进程在运行过程中,请求和释放资源的顺序不当,也同样会导致死锁。
信号量使用不当也会造成死锁。
(3)死锁产生的必要条件
昨天面试的时候短路遗忘的知识点(小声)。
产生死锁必须同时满足4个条件,只要其中一个不成立,死锁就不会产生。
-
互斥条件。如果某个资源无需互斥访问,自然就不存在对它的竞争了。
-
不剥夺条件。
-
请求和保持条件。进程已经保持了至少一个资源,而在提出新的资源请求的时候,该资源已被其他进程占用,此时当前进程被阻塞;但是它对自己已经获得的资源保持不放。
我理解这一条件和不剥夺条件的区别是,请求和保持条件允许进程可以保持资源不放,但是其他进程可能强行剥夺;如果你保持不放,且外人不能剥夺的话,就可能陷入僵局。
-
循环等待条件。存在一种进程资源的循环等待链,链中每个进程已获得的资源同时被链中下一个进程所请求。直观上看,循环等待条件似乎和死锁的定义一样,其实不然。按死锁定义所构成的等待环要求的条件更严格,它要求 Pi 等待的资源必须由 Pi+1 来满足,循环等待条件则无此限制。例如,系统中有两台设备, P0 占有一台, Pk 占有一台, Pn 请求这一设备,则这一设备可以从 P0 处获得,也可以从 Pk 处获得;虽然 P0 到 Pn 构成了一个等待圈,但等待圈外的设备 Pk 只要释放了这一设备,就打破了等待。因此,循环等待条件只是死锁的必要条件。
3.3 死锁的处理策略
(1)死锁预防
打破四个必要条件中的某一个,即可完全防止死锁的出现。
(2)死锁避免
注意“避免”和“预防”的区别。
在资源的动态分配过程中,采用某种方法(如银行家算法)来防止系统进入不安全状态,从而避免死锁。
(3)死锁的检测和解除
事先不采取任何限制性措施,允许进程在运行过程中发生死锁。通过系统的检测机构及时地检测出死锁的发生,然后采取某些措施解除死锁(剥夺资源、杀死进程、进程回退)。
周末是如此的Relaxed,今天又只记录了一个知识点,睡觉去也~
Reference
[1] 王道论坛.2021年操作系统考研复习指导[M].北京:电子工业出版社,2020:129::131
基本上一整天都在弄博客样式,折腾来折腾去,没有太大的改观······
4 malloc和new的区别
C++经典问题之一。
(1)是否调用构造函数。 malloc 为一个对象申请空间时,不会自动调用它的构造函数;而 new 会自动调用构造函数。同时,使用 new 申请一个对象数组时,会对每一个单元进行构造函数的调用,如下所示:
A* ptr = new A[10]; // 对每一个对象调用构造函数
delete[] ptr; // new数组的时候要搭配 delete[]
(2)一个是函数,一个是运算符(operator new)。 malloc 虽然是函数,但是它不允许重载;而 new 可以被重载。
(3)返回类型不同。 malloc 返回一个 void* 类型的指针,指向申请的那块空间;而 new 返回的是一个 确切的 对象指针。
(4)错误处理。 malloc 申请内存失败之后,会返回一个空指针 NULL ;而 new 申请内存失败后,会抛出 bad_alloc 异常。
(5)内存区域。 malloc 从堆中申请内存;而 new 会从 自由存储区(free store) 上申请内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。自由存储区的具体性质,取决于 new 运算符的实现方式,它本身也可以是堆。
(6)申请的大小。 malloc 需要调用者传入要申请的内存大小;而 new 申请的空间大小由编译器自动计算。
(7)更改大小。 malloc 允许通过 realloc() 函数更改缓冲区大小,假如要将缓冲区变大,系统会分配一块更大的空间,然后将当前缓冲区中的内容复制过去;而 new 不允许更改申请到的缓冲区的大小。
Reference
5 虚函数
虚函数一般在继承的场景下发挥作用。基类声明一个虚函数,子类重载这一函数,这样一来,当我们使用一个基类指针指向子类,并且希望调用这一函数的时候,得到的就是子类重载过的函数。
实际上,虚函数的意义就在于能够使得函数调用合乎逻辑,而不必考虑指针的类型。
虚函数的解析在运行的时候完成。
以下有几个虚函数的使用原则:
- 不能是
static函数; - 可以是其他类的友元函数;
- 使用基类指针或者引用来调用虚函数,以获得 运行时多态(run time polymorphism) ;
- 一般在基类定义、子类重载,但没有强制要求子类进行重载,在这种情况下,就和普通的函数继承没有区别;
- 可以有 虚析构函数(virtual destructor) ,但不能有 虚构造函数(virtual constructor) 。
夜已深了,且先休息去,来日再作补充~
Reference
2021-07-26
今天做题,学习了 【最长递增子序列】 的解法、之后AC了一道困难题!准备新开一篇难题本讲讲这道题: 1713. 得到子序列的最少操作次数 - 力扣(LeetCode) (leetcode-cn.com)
所以就鸽了鸽了~
2021-07-27
今天投简历,改完之后夜深了;明天留公司,估计也没有新的知识点学习。希望昨天说的文章能尽快完成吧。
既然啥知识点都没学,就简单讲一下每日一题吧。今天的每日一题是 671. 二叉树中第二小的节点 - 力扣(LeetCode) (leetcode-cn.com)
如何找到【第二小】的节点,下午折腾了一段时间;晚上回来,稍作考虑,可以直接使用排序+遍历的方法,找到第一个与左邻居不同的元素即可。
两次遍历的情况有一点问题,测试用例有一组 [2,2,2147483647] ,用 INT_MAX 初始化答案,找最小值的办法是行不通的,出题人属实很有水平。
答案里还有人直接使用 set ,属于是把STL玩明白了,我以后也要好好再学一下STL o(╥﹏╥)o
2021-07-28
今天公司留宿,不更新是理所当然的吧~ 今日的每日一题是 https://leetcode-cn.com/problems/all-nodes-distance-k-in-binary-tree/ ,中等题,一时间没有思路;看了题解之后发现二叉树可以转为图,这样就比较简单了。 一开始想用邻接矩阵,但是一个节点实际上只可能有三条边,那就使用dfs先存下这个节点的父节点,这样一个节点的所有邻居就全都可以找到了(两个子节点加上一个父节点,最多只有三个邻居);构造完了一个抽象意义上的“图”,使用BFS找目标距离的节点即可。
2021-07-29
谌龙翻盘李梓嘉!姜还是老的辣!
今天的知识点启发于白天的工作中,实际上并不是非常的重要,仅稍作记录。
6 FTP与SFTP
FTP 是文件传输协议(File Transport Protocol)的简写,使用 C/S 架构在web服务器和FTP客户端之间进行文件传输。FTP使用两个独立的连接,分别是命令连接和数据连接,前者用于传输指令,后者用于传输数据(文件)。实际上,双连接的机制在使用socket编程来实现文件传输功能时,是非常有意义的:当服务器发送完文件之后,可以直接关闭文件连接的socket,这样命令连接就知道文件传输已经完成,可以进行下一步工作了。
默认情况下,FTP没有加密,也就意味着 中间人攻击 的可能性。
SFTP 是SSH File Transport Protocol的简写,或者也被成为Secure File Transport Protocol。它提供与FTP一样的功能,但基于SSH而非C/S架构的FTP实现。SFTP只使用一个连接,并要求用户使用用户名/密码或者SSH密钥的方式进行授权。
由于实现方式的不同,FTP使用的端口是传统的21,而SFTP使用与SSH相同的22端口。
[1] FTP vs SFTP: What’s the Difference? Which One Should You Use? (kinsta.com)
7 LeetCode 987. 二叉树的垂序遍历
因不可抗力断更,昨天重感冒了······
今天仍然没好,仅对每日一题进行记录。
今天的每日一题是 987. 二叉树的垂序遍历 - 力扣(LeetCode) (leetcode-cn.com)
题目给的数据属于是少了,针对一千个二叉树节点,我们使用一个 multimap 来进行 列 → Node 的映射,注意这里的 Node 指的是自定义的数据结构:
typedef struct _node {
int val;
int row;
} Node, *PNode;
我们使用 multimap 来将某个列上的所有节点存储起来,使用 Node 来记录节点所在的行和值。这样,我们遍历完成之后得到的 multimap 就能够根据一个列值取出这一列上的所有节点;我们利用这些 Node 的行和值进行排序,正如题意所说的:
二叉树的 垂序遍历 从最左边的列开始直到最右边的列结束,按列索引每一列上的所有结点,形成一个按出现位置从上到下排序的有序列表。如果同行同列上有多个结点,则按结点的值从小到大进行排序。
这里注意 multimap 的几个用法:
multimap.emplace(key, value); // 插入值
multimap.equal_range(key); // 返回key值对应的所有value,返回值是一个pair,首元素是区间起点,次元素是区间终点的后面
独立自主完成的困难题,AC代码还是要贴一下~
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
typedef struct _node {
int val;
int row;
} Node, *PNode;
multimap<int, Node> col2node;
void dfs(TreeNode* root, int row, int col)
{
Node n;
n.val = root->val;
n.row = row;
col2node.emplace(col, n);
if (root->left)
dfs(root->left, row + 1, col - 1);
if (root->right)
dfs(root->right, row + 1, col + 1);
}
static bool cmp(Node& a, Node& b)
{
if (a.row < b.row)
return true;
else if (a.row == b.row)
return a.val < b.val;
else
return false;
}
vector<vector<int>> verticalTraversal(TreeNode* root) {
dfs(root, 0, 0);
vector<vector<int>> res;
for (int c = -1000; c <= 1000; c++)
{
if (col2node.count(c))
{
auto ret = col2node.equal_range(c);
vector<Node> sortedNodes;
vector<int> tmp;
for (auto a = ret.first; a != ret.second; a++)
{
sortedNodes.push_back(a->second);
}
sort(sortedNodes.begin(), sortedNodes.end(), cmp);
for (auto n : sortedNodes)
{
tmp.push_back(n.val);
}
res.push_back(tmp);
}
}
return res;
}
};
2021-08-01
建军节,伟大的人民军队万岁!
8 C++中的static关键字
我们知道,函数的局部变量空间分配在栈上,函数运行结束之后这些变量的空间就会被释放掉;当我们需要保存函数上一次调用时变量的状态,就需要将这个变量放到另一块存储空间上,这就是 static 关键字的作用。
static 变量存储在静态存储区,在程序结束之前都不会被释放。即使一个函数被多次调用,其中的 static 变量也始终只进行了一次内存分配,且它的值可以保持上一次调用时的样子。
static 关键字用于定义一个类中的成员变量的时候,有其独特的影响。由于 static 变量存储在一块独立的区域,所有类对象都共享这一个变量。如以下的例子所示,所有 GfG 类型的实例都共享 static 变量 i 。
// C++ program to demonstrate static
// variables inside a class
#include<iostream>
using namespace std;
class GfG
{
public:
static int i;
GfG()
{
// Do nothing
};
};
int main()
{
GfG obj1;
GfG obj2;
obj1.i =2;
obj2.i = 3;
// prints value of i
cout << obj1.i<<" "<<obj2.i; // Get 3
}
正因如此, 不允许在类的构造函数中对 static 类型的成员变量进行操作 。类中的 static 变量应该由用户在外部使用作用域运算符进行赋值。
如 int GfG::i = 1; 。
由以上的分析我们可以进一步推理,static 类型的类对象也具有全局的生命力,它的析构函数只会在程序结束的时候被调用。
再进一步推理,static 类型的函数也具有全局的生命力,当然,对函数讨论“生命力”没什么意义。
在一个类中, static 类型的成员函数正如 static 类型的成员变量那样,被所有对象(实例)所共享。我们可以使用 className.functionName 的形式来调用这个函数,不过还是首推作用域运算符 className::functionName 的方式来进行调用。由于所有的实例都共享这么一个 static 函数,它自然只能访问 static 类型的成员变量,或者其他 static 类型的成员函数;设想,所有的实例都来调用这个函数,然后它去访问一个非全局共享的变量,那么这个函数怎么知道这个变量应该属于哪个实例的呢?
Reference
9 分组密码——DES
9.1 简介
分组密码(块密码)是将明文消息编码表示后的二进制序列,划分成固定大小的块,每块分别在密钥的控制下变换成等长的二进制序列。
注意,尽管一些传统加密算法也进行分组,但它们并不是分组密码。例如,Vigenere加密算法的密钥也可以自定义块的大小,但它不属于分组密码。
分组密码加解密的设计有如下几个要求:
- 分组足够长。 根据分组长度
n,每一组中的元素个数2^n要足够对抗明文穷举攻击。 - 密钥长度足够长。 密钥长度
k,则密钥有2^k种情况,需要足够对抗密钥穷举攻击。但密钥长度不能太长,否则不利于管理和加解密速度。 - 置换算法足够复杂。 置换算法要足以对抗差分攻击和线性攻击等,使得攻击者只能进行穷举。
- 加解密运算简单,利于硬件实现。
- 一般无数据扩展,即明文和密文长度相同。
Shannon提出了三个分组密码的设计思想——混乱、扩散和乘积密码。
- 混乱。 可以理解为”搅拌机“,指在加密过程中明文、密钥以及密文之间的关系尽可能复杂,以防密码破译者采用统计分析法进行破译攻击。
- 扩散。 每1比特明文的变化尽可能多地影响到输出密文序列的比特,以便隐藏明文的统计特性。扩散的另一层意思是每1位密钥也尽可能影响到较多的输出密文比特。简而言之,扩散就是希望密文中的任一比特都要尽可能与明文和密钥的每一比特相关联。
- 乘积密码体制。 针对嵌套加密的一系列原则。此处省略。
9.2 分组密码的迭代结构
分组密码有两种迭代结构:Feistel网络结构和SP网络结构。
Feistel网络结构的加密办法如下:
-
将明文分组分割成长度相同的两块:(L0, R0)
-
对每一轮,i=0,1,…n
Li+1 = RiRi+1 = Li ⊕ F(Ri, Ki) -
加密后的密文为 (Rn+1, Ln+1)
解密办法与加密办法相反:
-
对于密文(Rn+1, Ln+1),每一轮 i=n,n-1,…0
Ri = Li+1Li = Ri+1 ⊕ F(Li+1, Ki) -
解密出 (L0, R0)
SP网络结构是代换-置换网络的简写。它由两个基本组件S盒和P盒组成。S盒进行代换操作,起到混乱作用;P盒进行置换操作,起到扩散作用。每一轮迭代中都先经过S盒、再经过P盒。
需要注意,置换不等于扩散。置换本身并不改变明文在单个字符或置换分组上的统计特性。但是,经过了多轮代换-置换的结合,就产生了扩散作用。
9.3 DES
DES的初始密钥长度为64位,但有效密钥为56位,其中第8/16/24/32/40/48/56位是奇偶校验位。
流程如下图所示:
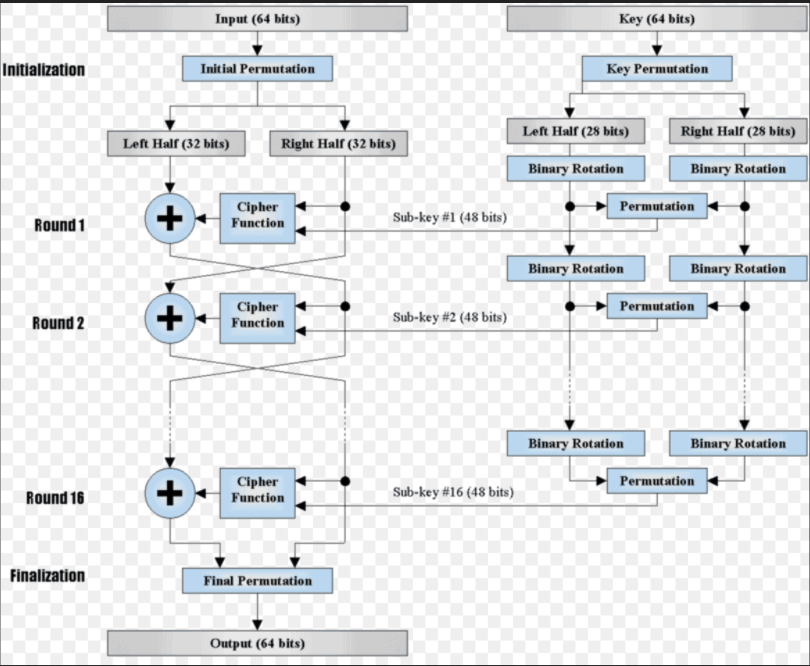
DES的初始置换Initial Permutation是固定的,它的作用是将原明文块的位进行换位。完成加密之后,要使用它的逆置换将其换回来,置换表如图所示:

DES一轮迭代过程如图所示,其遵循了Feistel网络结构,轮函数总共经历了扩展置换-密钥加-非线性代换-线性置换四个步骤。
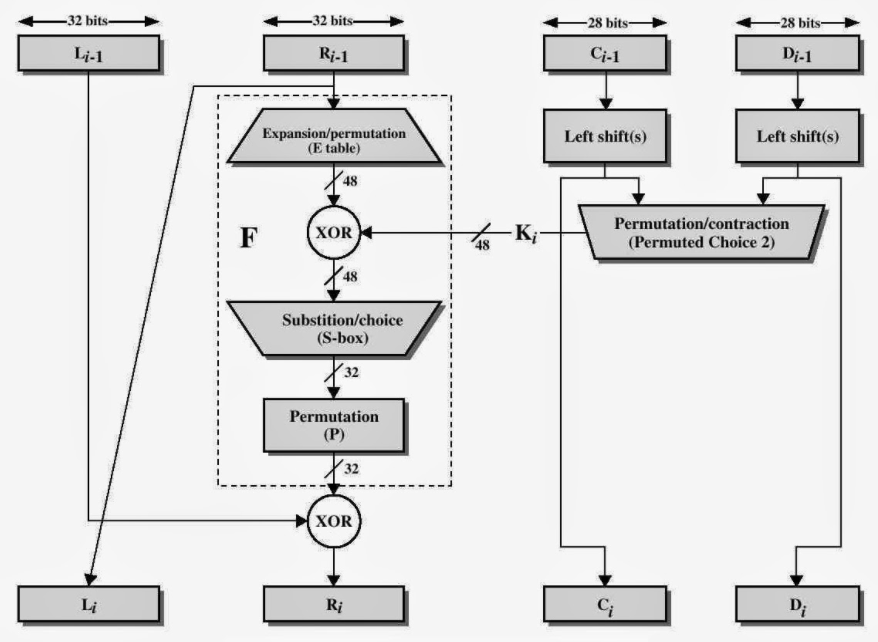
扩展置换又称E盒,将32位输入扩展为48位输出。E盒在DES算法上最基本地是要将输入扩展为与轮密钥相同的48比特,而更进一步,由于E盒的1位输入可能影响2个S盒的输入,能够更快地实现血崩效应。
代换盒又称S盒,是DES中唯一的非线性部分。经过S盒的代换,E盒扩展生成的48位数又压缩回32位。
最后的P盒没有太多探讨的意义,就是一个32位的置换表。
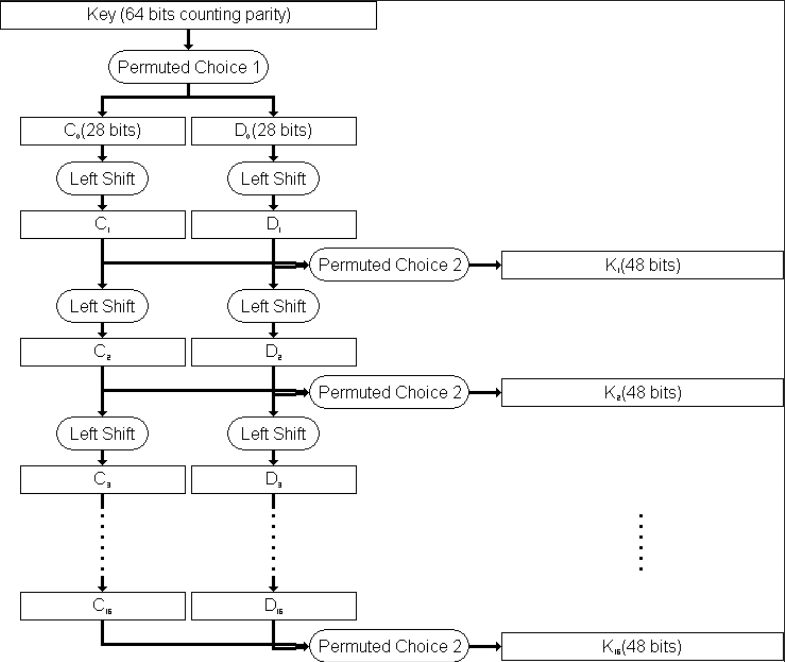
DES的密钥编排如下图所示,首先将64位密钥进行PC-1置换,然后根据轮数进行左移,其中,第1/2/9/16只移动1位,其余轮数移动2位。最后,56位密钥经过PC-2置换得到48位密钥。
关于DES的安全性问题,暂且不予记录了~
10 笔试复盘
晚上参加了Shopee的笔试,果然安全拉胯,编程AK……
编程题实际上也不难,第一题估计有个LeetCode的中等偏上,予以记录吧。
有一个整数 n 和一个整数 k ,现在要将 n 分成 k 份,每份至少有一个元素,求总共有多少种分法。注意,分割的办法不考虑顺序,例如将 7 分成 3 份,其中 1,1,5 和 5,1,1 或 1,5,1 属于同一种分法。
1 <= n <= 2001 <= k <= 7
这题我使用了三维记忆化搜索,rec[n][k][startswith] 表示将 n 分成 k 份,每一份的元素至少要大于 startswith 。
假设要将 7 分成 3 份,我们可以将其转化为将 6 分为 2 份,每份至少从 1 开始,或者将 5 分为两份,每份至少从 2 开始……
不好解释,直接放代码:
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
int record[210][8][210];
int d(int n, int k, int startswith)
{
// cout << n << " " << k << " " << startswith << endl;
if (record[n][k][startswith])
return record[n][k][startswith];
if (startswith * k > n)
return 0;
if (k == 1)
return 1;
int res = 0;
for (int start = startswith; start <= n / 2; start++)
{
res += d(n - start, k - 1, start);
}
record[n][k][startswith] = res;
return res;
}
int divide(int n, int k) {
// write code here
return d(n, k, 1);
}
int main()
{
int n, k;
n = 200;
k = 7;
cout << divide(n, k) << endl;
system("pause");
}
本场笔试也暴露出了一些安全理论上的缺陷,之后有空进行总结。今天就先到这里啦~
Reference
[1] 谷利泽,郑世慧,杨义先.现代密码学教程(第2版)[M].北京:北京邮电大学出版社,2019
2021-08-03
今天将昨天的笔试题整理了一下,还有些题目找不到答案,明天继续~
2021-08-14
断更将近2周,陆续恢复吧……
11 LeetCode 1583. 统计不开心的朋友
1583. 统计不开心的朋友 - 力扣(LeetCode) (leetcode-cn.com)
今天的题目是个模拟题,然而我卡了半天没有做出来……
这里的一个关键是建立二维映射 rank[x][y] 表示 y 在 x 心中的优先级,数值的话直接按照 preferences[x] 中 y 所处的下标即可。
对于一个 x 来说,我们可以找到所有位于 rank[x][y] 之前的数 u ,即 x 心中比 y 更加优先匹配的对象,再找到 u 的现有对象 v ,比较 rank[u][x] 和 rank[u][v] 的大小。如果 rank[u][x] < rank[u][v] ,说明 u 也更希望和 x 进行匹配,那么依照题意, x 就是不开心的。
之前对于不开心的理解,是 x 不开心,则 u 应该也不开心,这样就比较复杂了。我们只考虑 x 开不开心,把 u 放到之后进行考虑,反而简单一些。
代码就不放了,WA了两次的中等题,我现在属实不怎么开心。
12 LeetCode面试题 04.05. 合法二叉搜索树
https://leetcode-cn.com/problems/legal-binary-search-tree-lcci/
这题属实顶不住了……出题人给那么多 INT_MAX 的测试用例干啥???
希望检查一颗树是否是二叉搜索树,只需要考虑它的左节点是否满足一定范围、右节点是否满足一定范围,然后按照递归的思路向下进行,类似于深搜。
初始情况下(即考虑根节点的时候),它的数据范围应该是 -INF ~ +INF ,然而,出题人给了很多组 INT_MAX 和 INT_MIN 的测试用例,简单地使用这两个宏作为初始数据范围,会挂掉。(丢雷楼某)
因此,我们的递归函数中表示数据范围的参数需要定义为 long long 类型,然后在初始传入的时候,传个比 INT_MAX 还大的数 (long)INT_MAX + 1 。
我giao!
13 LeetCode5845. 你能穿过矩阵的最后一天
题目链接 5845. 你能穿过矩阵的最后一天
《关于思路正确而代码质量太差导致我TLE从而只做出了周赛签到题这件事》
倒不完全认为它是道困难题,毕竟第一时间是有思路的。
首先,二分答案是第一想法,TLE的风险也同时存在。
对于一个答案 day 来说,如何判断在这一天里能否从第一行到达最后一行呢?BFS啊!
我们在 day 这一天的进行BFS寻路,从第一行的任意一个起点出发,如果某个起点能到达最后一行的某个终点,说明在 day 这一天还能够穿过矩阵,继续进行二分。
寻路时,在 day 这一天被水淹没的格子就走不了了,这里有一个关键问题:如何验证某个格子是否被水淹没?最开始,我使用了一个 map 来表示某个格子是否被淹,但这样我们需要额外引入 O(logn) 的复杂度,会超时。比赛结束之后查看题解,发现直接用 visited 数组来把被淹过的格子禁用掉即可……
总之,比赛的时候提交的代码质量确实差了,还得多练练吧。
AC代码
class Solution {
public:
vector<vector<int>> g_cells;
int g_row, g_col;
typedef struct _pos {
int x, y;
friend bool operator< (const _pos& a, const _pos& b) {
if (a.x != b.x)
return a.x < b.x;
else
return a.y < b.y;
};
} Pos, * PPos;
map<Pos, int> watered;
bool hasRoute(int day)
{
// cout << "day " << day << endl;
vector<pair<int, int>> dirs = {
{1, 0},
{0, 1},
{-1, 0},
{0, -1}
};
vector<vector<int>> visited(g_row, vector<int>(g_col, 0));
queue<Pos> q;
Pos head;
// 通过设置visited数组来使得被淹没的方块无法访问
for (int i = 0; i < day; i++)
{
visited[g_cells[i][0] - 1][g_cells[i][1] - 1] = 1;
// cout << g_cells[i][0] - 1 << "," << g_cells[i][1] - 1 << " watered\n";
}
for (int start = 0; start < g_col; start++)
{
head.x = 0;
head.y = start;
// 该起点被淹了
if (visited[head.x][head.y])
continue;
q.push(head);
visited[head.x][head.y] = 1;
}
while (!q.empty())
{
head = q.front();
q.pop();
// cout << head.x << "," << head.y << endl;
if (head.x == g_row - 1)
return true;
for (auto d : dirs)
{
Pos nxt;
nxt.x = head.x + d.first;
nxt.y = head.y + d.second;
// 坐标合法,且还未被淹
if (nxt.x < g_row && nxt.x >= 0 && nxt.y < g_col && nxt.y >= 0 && !visited[nxt.x][nxt.y])
{
// cout << "goto: " << nxt.x << "," << nxt.y << endl;
// cout << "This point is watered at day " << watered[nxt] << endl;
q.push(nxt);
visited[nxt.x][nxt.y] = 1;
}
}
}
return false;
}
int latestDayToCross(int row, int col, vector<vector<int>>& cells) {
g_row = row;
g_col = col;
Pos p;
g_cells = cells;
int left = 0;
int right = cells.size() - 2;
while (left <= right)
{
int mid = (left + right) >> 1;
if (hasRoute(mid))
left = mid + 1;
else
right = mid - 1;
}
return left - 1;
}
};
14 LeetCode576. 出界的路径数
最近总是挂每日一题,心态受到了不小的影响啊……
wdnmd记忆化搜索还卡时间复杂度是怎么回事??
关键剪枝:当使用 maxMove 步直上/直下/直左/直右都无法到达边界的时候,直接返回 0 。
淦!!
15 数据库并发导致的问题
在网上若干资料中看到了相互矛盾的解释,直接怒而翻教材,应该是比较权威的了吧……
由于 事务是并发控制的基本单位 ,其ACID特性需要得到保证。并发操作带来的数据不一致性包括丢失修改、不可重复读和读“脏”数据。
15.1 丢失修改
两个事务 T1 和 T2 读入同一数据并修改, T2 提交的结果破坏了 T1 提交的结果,导致 T1 的修改被丢失。
15.2 不可重复读
事务 T1 读取数据后,事务 T2 执行更新操作,使 T1 无法再现前一次读取结果。根据 T2 执行的操作来看,不可重复读包括三种情况:
(1)事务 T1 读取某一数据后,事务 T2 对其进行修改。则使得 T1 两次读取的数据是不一样的。
(2)事务 T1 读取某一数据后,事务 T2 对其进行删除。当 T1 再次读取数据时,发现某些数据消失了。
(3)事务 T1 读取某一数据后,事务 T2 对其进行增添。当 T1 再次按照相同的条件读取数据时,发现多了一些记录。
后两种不可重复读有时也称为 幻影 现象。
15.3 读脏数据(脏读)
脏读是指事务 T1 修改某一数据并将其写回磁盘,事务 T2 读取同一数据后, T1 由于某种原因被撤销,这时被 T1 修改过的数据恢复原值, T2 读取到的数据与数据库中的数据就不一致了,称这些数据为 脏数据 。
15.4 不可重复读和幻读的区别
根据 [15.2节](#15.2 不可重复读) 中对不可重复读的描述,我们可以将后两种情况称为 幻读 。
网络上的各种资料,多用 不可重复读 来指代第一种情况,而用 幻读 来指代后两种情况。这样,不可重复读和幻读的区别就在于:不可重复读指的是数据内容的不一致,而幻读指的是数据数量的不一致。
在使用锁来实现隔离机制的时候,针对不可重复读只需要使用 行锁 ,而针对幻读的现象需要使用 表锁 。
15.5 四个隔离等级
事务的隔离级别有四,它们对脏读、不可重复读和幻读的解决效果分别如下:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 是 | 是 | 是 |
| 读已提交 | 否 | 是 | 是 |
| 可重复读 | 否 | 否 | 是 |
| 串行化 | 否 | 否 | 否 |
16 程序装入和链接
创建进程首先要将程序和数据装入内存。将用户源程序变为可在内存中执行的程序,通常需要以下几个步骤:
- 预处理。展开头文件、宏替换、去掉注释、条件编译。
- 编译。将代码转换成汇编代码,并在这个步骤中完成两件工作:
- 每个文件中产生一个函数地址符表,存储着当前文件内包含的各个函数的地址;
- 调用函数的代码会编译为
call指令,而call指令跟随的地址上是一条jmp指令,jmp指令跟随的地址才是被调用函数的地址。为call指令补充上地址是在链接的时候才完成的。
- 汇编。将编译出的文件转换成机器码。
- 链接。将编译后形成的一组目标模块及所需的库函数链接成一个完整的装入模块。
- 装入。将程序装入内存执行。
程序的链接有三种方式:
- 静态链接。在程序运行前,将各目标模块和所需的库函数链接成一个完整的可执行程序,以后不再拆开。
- 装入时动态链接。装入内存时边装入边链接。
- 运行时动态链接。对于某些目标模块的链接,是在程序执行中需要该目标模块时才执行的。其优点是便于修改和更新,便于实现对目标模块的共享。
模块在装入内存时,也有三种方式:
- 绝对装入。在编译时,若知道程序将驻留在内存的某个位置,则编译程序将产生绝对地址的目标代码。绝对装入程序按照装入模块中的地址,将程序和数据装入内存。该方式只使用于单道程序环境,绝对地址可在编译或汇编时给出,也可由程序员直接赋予。
- 可重定位装入。多道程序环境下,模块中使用的地址一般是相对地址(相对于起始地址
0)。可重定位装入会在装入时将模块中的相对地址修改为绝对地址(相对于装入的位置)。**装入时对目标程序中指令和数据的修改过程称为 重定位 ,地址变换通常是在装入时一次性完成的,又称为 静态重定位 **。 - 运行时动态装入。装入程序把模块装入内存后,并不立即把装入模块中的相对地址替换为绝对地址,而是把这种转换推迟到程序真正要执行时才进行。 这种方式需要一个重定位寄存器的支持 。
Reference
[1] 王道论坛.2021年操作系统考研复习指导[M].北京:电子工业出版社,2020:129::131
17 设计模式简述
设计模式(Design Pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
设计模式的目的是为了可重用代码,提高代码的可扩展性和可维护性。
设计模式主要有几种类型:
- 创建型模式 。该模式重点关注如何创建对象,在创建对象时隐藏创建逻辑,从而使对象的创建和使用相互分离。
- 结构型模式 。该模式重点考虑类和对象的组合,目的是获得更好、更灵活的结构。
- 行为型模式 。该模式重点关注算法和对象之间的职责分配,通过安排对象之间的合理通信来更好地完成整体的任务。
设计模式有如下几个原则:
-
开闭原则 。软件 对扩展开放,对修改关闭 。简而言之,程序在进行升级的时候,只对现有模块进行扩展,而尽量不对原有代码进行修改。
-
里氏替换原则 。子类能够完全替换父类。显然,只有当子类替换掉父类,且原有的方法不受影响时,父类才算真正得到了复用。
-
依赖倒转原则 。针对接口编程,依赖于抽象而不依赖于具体。
-
接口隔离原则 。使用多个隔离的接口,比使用单个接口更好。我认为该原则的思想是将复杂问题拆解,降低类之间的耦合。
-
迪米特法则 。又称最小知道原则,一个实体应该尽量少地与其他实体发生作用,使得系统模块相对独立。
-
合成复用原则 。尽量使用合成/聚合的方式,而不是使用继承。而若使用继承,则需要遵守里氏替换原则。
注、使用继承的方式进行复用虽然比较简单,但破坏了父类的封装性。使用合成或聚合复用,指的是将已有对象纳入新对象中,使之成为新对象的一部分,该方法又被称为“黑箱”复用。
Refernence:
[1] [合成复用原则——面向对象设计原则 (biancheng.net)](http://c.biancheng.net/view/1333.html#:~:text=合成复用原则的重要性 1 它维持了类的封装性。因为成分对象的内部细节是新对象看不见的,所以这种复用又称为“黑箱”复用。,2 新旧类之间的耦合度低。这种复用所需的依赖较少,新对象存取成分对象的唯一方法是通过成分对象的接口。 3 复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。)
18 C++中的const关键字
无论 const 关键字出现在什么地方,不管它用于修饰指针、变量、函数或类,其核心作用都是防止它修饰的目标受到修改。
18.1 const变量
const 关键字指定一个变量的值为常值,编译器将禁止对这一变量的修改。
// constant_values1.cpp
int main() {
const int i = 5;
i = 10; // C3892
i++; // C2105
}
我们可以使用 const 关键字来代替 #define ,这一做法会使得编译器对这一常变量进行 类型检查 ,而使用宏定义得到的对象只是在编译之前进行预处理替换,没有类型检查。
如果此类变量作为一个类的成员变量,则必须使用 初始化列表 来进行初始化。
在C语言中, const 变量默认为 外部链接 类型,则其只能出现在单个 源文件 中;而C++中的 const 变量与之相反,而我们知道内部链接类型的变量可以出现在 头文件 中;当然,如果希望其他源文件也访问到这一 const 变量,则需要使用 extern 来声明。
const 关键字也可用于指针的声明当中:
// constant_values3.cpp
int main() {
char *mybuf = 0, *yourbuf;
char *const aptr = mybuf;
*aptr = 'a'; // OK
aptr = yourbuf; // C3892
}
以一种简单的方式来区分 常指针 和 常量指针 :如果 const 出现在星号 * 后面,则它修饰的是指针变量本身;如果 const 出现在星号 * 前面,则它修饰的是指针指向的变量。
如果难以区分,不妨从英文的角度出发,观察以下两个变量:
const char* p1; // pointer to constant data char* const p2; // constant pointer是不是好懂了一些?
18.2 const成员函数
声明一个带有 const 关键字的成员函数表明该函数是一个“只读”函数,其内部代码将不会改变任何成员变量。这类函数不能修改任何非静态变量、且只能调用其他的 const 函数。
声明和定义 const 函数的办法是在函数形参的小括号后面加上 const 关键字。
// constant_member_function.cpp
class Date
{
public:
Date( int mn, int dy, int yr );
int getMonth() const; // A read-only function
void setMonth( int mn ); // A write function; can't be const
private:
int month;
};
int Date::getMonth() const
{
return month; // Doesn't modify anything
}
void Date::setMonth( int mn )
{
month = mn; // Modifies data member
}
int main()
{
Date MyDate( 7, 4, 1998 );
const Date BirthDate( 1, 18, 1953 );
MyDate.setMonth( 4 ); // Okay
BirthDate.getMonth(); // Okay
BirthDate.setMonth( 4 ); // C2662 Error
}
19 OWASP top 10(2017)
19.1 注入
解释 :该漏洞的核心是缺乏对Web应用程序使用的数据的验证和清理。任何接受参数作为输入的内容都可能受到注入攻击。
防护 :
- 使用安全的API。
- 对输入设置白名单,或者相关输入验证。
- 转义特殊记录。
- 在查询中使用
LIMIT或其他SQL控件,防止SQL注入时大量地泄露记录。(考虑最坏情况……)
19.2 失效的身份认证
解释 :该漏洞的核心是身份认证机制在某处实现上存在问题。如使用单因素身份认证、使用弱口令、在用户注销之后没有及时清除Session、在URL中暴露会话ID等。
防护 :
- 多因素身份认证。
- 弱口令检查。
- 统一注册、凭据恢复等接口,防止用户枚举攻击。
- 会话ID的合理管理,如登录之后生成高度随机的会话ID、妥善存储(肯定不能出现在URL里……)、登出之后及时销毁。
19.3 敏感数据泄露
解释 :该漏洞的核心是密码算法的失效(Cryptographic Failures)。数据在 存储 、 传输 或 交互 过程中没有使用合理的加密算法进行保护,使得其中敏感数据被泄露。
防护 :
- 对没必要存储的敏感数据予以及时销毁,存储的敏感数据确保加密。
- 使用最新的、强大的算法、协议、密钥,且密钥妥善管理。
- 确保数据传输过程中受到加密保护,如使用HSTS。
19.4 XML外部实体(XXE)
解释 :许多较早的或配置错误的XML处理器解析了XML文件中的外部实体引用,攻击者可以利用这些外部实体窃取服务侧的内部文件和共享文件、实行内网扫描、远程代码执行和拒绝服务攻击(可以归纳为SSRF吗?)
防护 :
- 使用简单的数据格式(如JSON),避免对敏感数据进行序列化。
- XML库的版本检查,及时更新修复相关组件。
- 在XML解析器上禁用外部实体和DTD(文档定义类型)。
- 服务端实施白名单机制,对输入进行过滤和清洗。
19.5 失效的访问控制
解释 :Broken Access Control ,和19.2中的 Broken Authentication 是有区别的。个人理解,失效的访问控制主要是指攻击者已经具备了一个合法用户,只是他所对应的访问权限可以经由某种手段进行提升,从而访问某些未经授权的功能或数据。
防护 :
- 访问控制只有在服务端有效 。
- 除公有资源外,默认情况下拒绝访问其他资源。
- 建立一次性的访问控制机制,并在整个应用中不断重用他们。
- 建立访问控制模型以强制执行所有权记录,而不是接受用户创建、读取、更新或删除的任何记录(强制访问控制MAC?)。
- 记录失败的访问控制,并及时告警。
19.6 安全配置错误
解释 :顾名思义。这个问题是很常见的安全问题,通常由于不安全的默认配置、不完整的临时环境、开源云存储、错误的HTTP标头配置以及包含敏感信息的详细错误信息所造成的。
防护 :
- 实施安全的安装过程,如开发、测试、生产环境中保持相同安全配置,且口令不同。安装过程尽量自动化,以减小出错的可能。
- 搭建最小化平台,移除所有不必要的功能、组件、文件及示例。
- 检查和修复安全配置项来适应最新的安全说明、更新和补丁,并将其作为更新管理过程的一部分。检查过程中,特别注意云存储的权限。
- 向客户端发送安全指令,如安全标头(想到了CSP、HTTP-Only)。
19.7 跨站脚本(XSS)
解释 :网页中使用了用户提供的参数,且这些参数没有被妥善地转义,可能引发浏览器将这些参数当作原本网页中的脚本,予以执行。
防护 :
- 使用设计上就会自动编码来解决XSS问题的框架,如Ruby 3.0或React JS。了解每个框架XSS保护的局限性,并适当地处理未覆盖的用例。
- 根据HTML上下文对所有不受信任的HTTP请求数据进行转义 or 编码。
- 内容安全策略(CSP) ,如果不存在本地文件上传的其他漏洞,将绝杀。(大致思想是向客户端发送安全指令,限定只执行某些域名下的脚本)。
19.8 不安全的反序列化
解释 :序列化是将对象的状态信息转换为可以存储或传输的形式的过程。在序列号期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,来重建该对象。不安全的反序列化是指攻击者提供恶意的篡改过的对象,使得应用程序和API变得脆弱。
针对反序列化漏洞,主要有两种攻击形式:
- 在反序列化过程中改变应用逻辑或实现远程代码执行,称为 对象和数据结构攻击 ;
- 篡改序列化之后的数据,实现访问控制相关的攻击;
防护 :
- 唯一安全的架构是不接受来自不受信源的序列化对象。
- 可以考虑执行完整性检查,如对序列化对象进行数字签名,防止恶意对象创建或数据篡改。
- 将反序列化代码隔离在低特权环境中运行。
- 监控反序列化行为,记录反序列化的例外情况和失败信息。
19.9 使用含有已知漏洞的组件
解释 :组件(库、框架和其他模块)拥有和应用程序相同的权限。如果应用程序中含有已知漏洞的组件被攻击者利用,可能造成严重的数据丢失或服务器接管。
防护 :
- 移除不使用的依赖、不需要的功能、组件、文档。
- 利用各种工具来持续记录客户端和服务端以及它们的依赖库的版本信息。持续监控CVE等信息来判断已有组件是否有漏洞。
- 使用官方渠道安全地获取组件,并使用签名机制来降低组件被篡改或加入恶意漏洞的风险。
- 监控那些不再维护或不发布安全补丁的库和组件。
19.10 不足的日志记录和监控
解释 :不足的日志记录和监控,使得攻击者在系统中可以更隐蔽地驻留、攻击、横向移动、销毁证据。
防护 :
- 确保所有登录、访问控制失败、输入验证失败都能被记录到日志中去,并保留足够的用户上下文信息,以识别可疑或恶意账户,并为后期取证留足时间。
- 确保日志以一种能够被集中日志管理解决方案使用的形式生成。
- 确保高额交易有完整性控制的审计信息,且审计信息必须防止篡改或删除。
- 采用有效的监控和告警机制。
- 采用一个应急响应机制和恢复计划。