这是一篇初读时就给我留下深刻印象的文章,其中阐述的理念个人认为极具指导意义。在这元旦假期的最后一晚,重读此文,斗胆自译,贻笑大方尔尔。
《Clean Architecture: A CRAFTSMAN’S GUIDE TO SOFTWARE STRUCTURE AND DESIGN》——by Robert C. Martin
Chapter 5 OBJECT-ORIENTED PROGRAMMING
我们可以看到,对面向对象的设计原则(object-oriented)的良好理解和应用是一个良好架构的基础,但何为OO?
该问题的回答之一是“数据和方法的结合”。尽管这种论调到处被引用,它仍是一个令人很不满意的回答,因为它似乎隐约告诉人们 o.f() 在某些情况下是不同于 f(o) 的。这很荒谬,因为在Dahl和Nygaard于1966年把函数调用栈挪到堆上并发明OO以前,程序员们一直都将数据结构传入函数中去。
对于该问题(何为OO?)的另一常见回答是“一种对现实世界建模的方式”。这充其量是个含糊其辞的回答。“对现实世界建模”的真实含义是什么呢?而为什么我们需要这么做呢?也许这一回答希望表达的是OO使软件更贴近现实世界因而更易理解——但即使是这样的表述仍是含糊且过于宽泛了。它总的来说并没有告诉我们何为OO。
也有一些人回归到三个表达OO本质的“魔法”词汇上:封装、继承和多态。本质上是想说OO就是这三样东西的恰到好处的结合,或至少一门OO语言必须支持这三样特性。
那么就让我们逐一考察这三个概念吧。
封装?
封装 之所以被认为是OO基本定义之一,是因为面向对象语言对数据和方法提供了简洁高效的封装。封装的结果,是人们可以在数据和方法的外围画一条线,在线外面,数据被隐藏,只有一些方法是可见的。这一概念通常体现在一个类的私有数据和公有方法上。
但这一理念当然不独属于OO。实际上,在C语言中也有完美的封装,考虑这段代码:
// point.h
struct Point;
struct Point* makePoint(double x, double y);
double distance (struct Point *p1, struct Point *p2);
// point.c
#include "point.h"
#include <stdlib.h>
#include <math.h>
struct Point {
double x,y;
};
struct Point* makepoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx+dy*dy);
}
point.h 的用户并没有访问 struct Point 的成员的权限。他们可以调用 makePoint() 和 distance() 这两个函数,但不知道任何关于 Point 这个数据结构以及这些函数的实现细节。
这就是一个完美的封装——在一个 非OO 的语言上。C程序员对此习以为常。我们可以在头文件中声明数据结构和函数,在源文件中实现它们。用户不可访问源文件中的相关元素。
让我们看到面向对象的C++——C语言的完美封装被打破了。
C++编译器出于技术原因,要求将一个类的成员变量在这个类的头文件中声明。因而我们的 Point 程序变为这样:
// point.h
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
private:
double x;
double y;
};
// point.cc
#include "point.h"
#include <math.h>
Point::Point(double x, double y)
: x(x), y(y)
{}
double Point::distance(const Point& p) const {
double dx = x-p.x;
double dy = y-p.y;
return sqrt(dx*dx + dy*dy);
}
point.h 的用户能看到成员变量 x 和 y !编译器会阻止对它们的访问,但用户仍知道它们的存在性。例如,如果这些成员的命名被修改, point.cc 必须被重新编译!封装被打破了。
事实上,人们又通过引入 public 、 private 和 protected 关键字来部分地修复封装性,然而这仅是在编译器提出要在头文件中看到这些成员变量的技术需求之后,引入的一种必要技巧。
Java和C#直接完全弃用头文件/源文件的分离模式,因此更加削弱了封装性。在这些语言中,无法区分一个类的声明和实现。
出于以上原因,我们无法接受OO依赖强封装性这种说法,实际上许多OO语言仅有微小的或非强制的封装性。
OO当然十分依赖于程序员的良好行为,不擅自绕开封装对数据进行窥探。尽管如此,那些声称提供了OO的编程语言也仅仅是弱化了我们曾在C语言上享受的完美封装性而已。
继承?
如果OO语言并未为向我们提供更好的封装性,那它们至少确实向我们提供了继承。
好吧——某种程度上。继承实际上只是对一个特定域内的一组变量和方法的简单重复声明。这是一件C程序员在OO面世之前很久就可以手动实现的事。
考虑我们的 point.h 的C程序的补充:
// namedPoint.h
struct NamedPoint;
struct NamedPoint* makeNamedPoint(double x, double y, char* name);
void setName(struct NamedPoint* np, char* name);
char* getName(struct NamedPoint* np);
// namedPoint.c
#include "namedPoint.h"
#include <stdlib.h>
struct NamedPoint {
double x,y;
char* name;
};
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
}
// main.c
#include "point.h"
#include "namedPoint.h"
#include <stdio.h>
int main(int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint (1.0, 1.0, "upperRight");
printf("distance=%f\n",
distance(
(struct Point*) origin,
(struct Point*) upperRight));
}
仔细阅读 main 程序能够发现, NamedPoint 这个数据结构表现得就如同它是 Point 的子类一样。这是因为 NamedPoint 的前两个成员的顺序和 Point 一致。简言之, NamedPoint 可以完全假扮 Point ,因为它是 Point 的真子集且一比一保持了和 Point 一致的成员顺序。
此类技巧也是OO面世前的程序员们的基操。实际上,这一技巧也是C++实现单继承的法门。
因此我们可以不完全正确地说,说在OO语言被发明以前我们就有某种形式上的继承机制。我们有技巧,但它远不如真正的继承来的方便。此外,多继承也是只凭借这样的技巧很难去实现的东西。
另外再注意,在 main.c 中我强制将 NamedPoint 参数转换为了 Point 。在真正的OO语言中,这样的向上转换会是隐式的。
公平地说,尽管OO语言并没有带给我们完全新颖的东西,它仍使得数据结构的相互装扮变得方便许多。
回忆一下:我们在封装上给OO打了0分,在继承上也许可以打个0.5分,到目前为止这不是一个很高的分数。
但还剩一个属性需要考虑。
多态?
在OO语言之前,我们有多态吗?当然有。考虑如下简单的C代码:
#include <stdio.h>
void copy() {
int c;
while ((c=getchar()) != EOF)
putchar(c);
}
函数 getchar() 从 STDIN 中读数据。但 STDIN 是啥设备?同理 putchar() 向 STDOUT 中写数据, STDOUT 又是啥设备?这些函数是 多态 的——它们的行为取决于 STDIN 和 STDOUT 的类型。
STDIN 和 STDOUT 看起来就像Java风格的 interface (接口),对于每种设备均有实现。当然,示例C程序中并没有接口——所以对于 getchar() 的调用究竟是如何被传递到读取字符的设备驱动上的?
对此问题的回答十分直白。UNIX操作系统要求每种IO设备驱动实现五个标准函数: open , close , read , write 和 seek 。这些函数的签名对于每种IO驱动必须一致。
FILE 数据结构包含了五个指针来指向这五个函数。在我们的示例中,它可能长这样:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};
终端的IO驱动将实现这些函数,并在它们的地址空间内声明一个 FILE 结构,如下:
#include "file.h"
void open(char* name, int mode) {/*...*/}
void close() {/*...*/};
int read() {int c;/*...*/ return c;}
void write(char c) {/*...*/}
void seek(long index, int mode) {/*...*/}
struct FILE console = {open, close, read, write, seek};
现在如果 STDIN 被定义为一个 FILE* ,且它指向 console 结构,那么 getchar() 就可以有如下实现:
extern struct FILE* STDIN;
int getchar() {
return STDIN->read();
}
换言之, getchar() 只是调用了 STDIN 指向的 FILE 结构中的 read 指针所指向的方法。
这一简单技巧是OO当中所有多态机制的基础。在C++中,类中的每一个虚函数都在虚表 vtable 中有一个指针,对于虚函数的调用就通过虚表来转发。子类的构造函数可以将它们自己重载后的虚函数的指针加载到虚表里。
说到底多态就是对函数指针的应用。程序员们自冯诺伊曼架构在1940年代被首次实现后就一直在使用函数指针来实现多态行为。换言之,OO并未提供新的东西。
啊,但这又不完全正确。OO语言可能并未向我们提供多态,但它们使得多态安全和高效许多。
显式使用函数指针来实现多态行为的问题就在于函数指针是 危险的 。这种用法背后是一系列人为习惯。你必须记得按习惯去初始化这些指针,你必须记得按习惯去通过这些指针来调用你的函数。如果有程序员忘记了这些习惯,所导致的bug可能是极难定位和修复的。
OO语言解除了这些习惯的约束,也因此消除了风险。OO语言使得多态变得普普通通。这一事实蕴含着C程序员梦寐以求的一种极大能量。在这一基础上,我们可以得出OO强制改变了控制流这一结论。
多态的力量
多态的伟力何在?为了更好地欣赏其魅力,让我们再考虑下示例的 copy 程序。当一款新的IO设备被创建时,程序将会发生什么?假设我们需要使用 copy 来将数据从手写识别设备拷贝到语音输出设备,我们需要如何改变这一程序以使它适用于这些新的设备?
我们完全不需任何改变!实际上,我们甚至不需要重新编译这个程序。为什么?因为 copy 程序的源码并不依赖于IO设备的源码。只要这些IO设备实现了 FILE 结构所定义的五个标准函数, copy 程序就能愉快地使用它们。
简单说,IO设备成为了 copy 程序的插件。
为什么UNIX操作系统要使IO设备成为插件呢?因为我们在1950年代末期认识到,我们的程序应该是 设备独立 的。Why?因为我们写了太多的 设备依赖 的程序,最终发现我们只是需要这些程序用不同的设备完成同样的工作。
例如,我们会写一款需要从一叠磁卡中读取数据、并输出到一叠新的磁卡上的程序。后来,用户不再给我们磁卡并开始给我们磁带了。这简直太不方便了,因为这意味着重写原有程序的很大一部分。假如相同的程序不依赖于磁卡,就会方便许多。
插件式架构就是被发明来支持这样的IO设备独立的,并在几乎所有操作系统上都得到了实现。即便如此,多数程序员并没有将这个理念贯彻到他们的程序中去,因为使用函数指针是危险的。
OO允许插件式架构在任意场合、对任意对象使用。
依赖倒置
设想还没有一个安全方便的多态机制之前,程序会是什么样的。在典型的调用树中,主程序调用高层函数,高层函数再调用中层函数,然后调用底层函数。在这样的调用树中,源码依赖的方向不可避免地沿着控制流的方向。
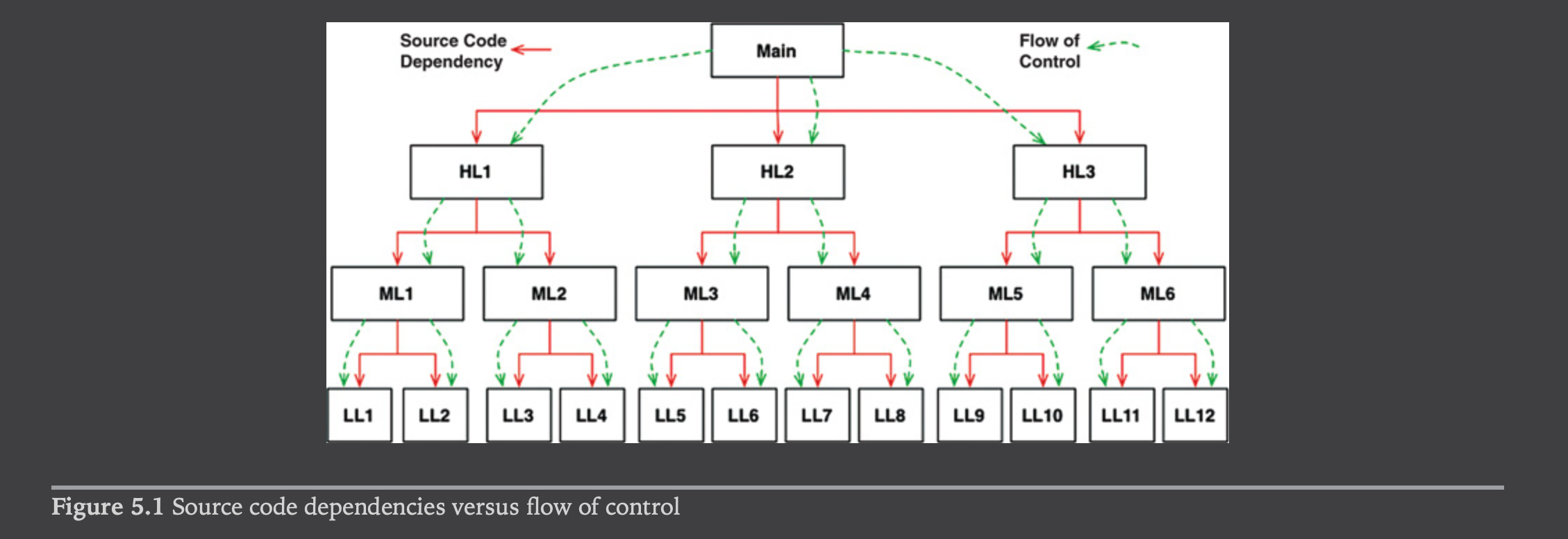
main 函数要调用高层函数时,它必须要引用包含了目标函数的模块。在C语言中,这就是 #include 语句。在Java中,这是 import 语句。在C#中,这是 using 语句。实际上,一切调用者都需要引入包含了被调者的模块。
这一需求给软件架构留下了很小的可选择余地。程序的控制流被系统行为所限定,源码依赖被控制流所限定。
当多态入场,一切就有所不同。
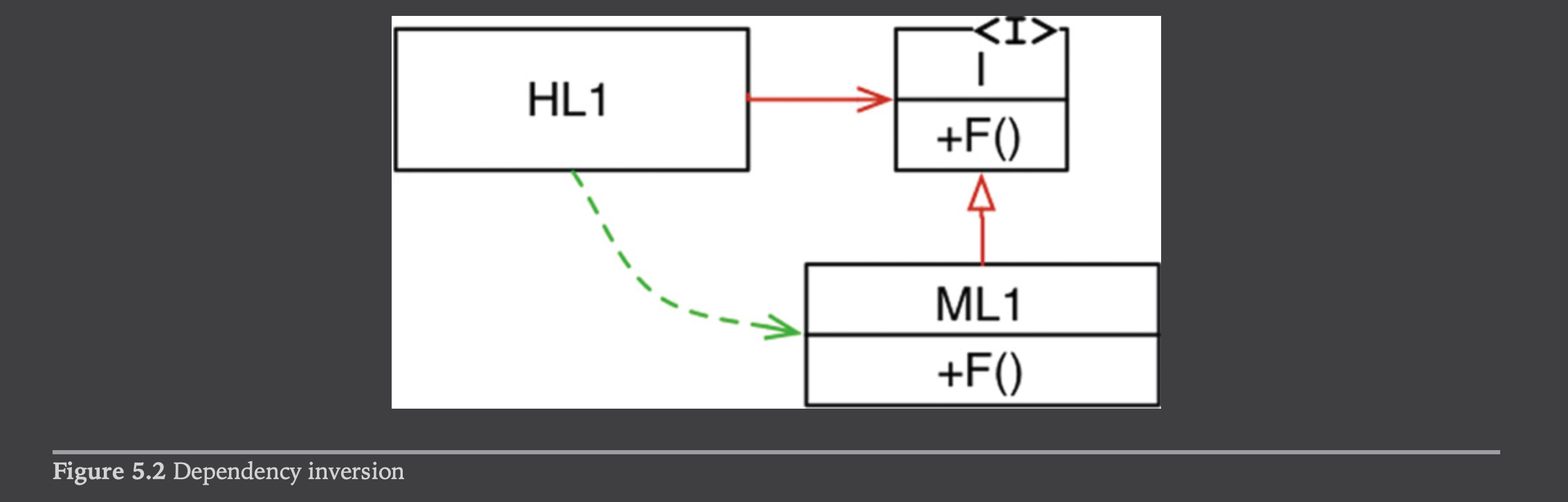
在图 5.2 中,模块 HL1 调用了模块 ML1 中的 F() 方法。图示里通过一层接口来完成函数调用实际上是源码层面的矫揉造作,在运行时,接口并不存在,HL1 只是简单地调用 ML1 当中的 F() 方法。
注意,ML1 和接口 I 之间的源码依赖(继承关系)指向控制流的反向。这称为 依赖倒置 ,它对软件架构的影响是巨大的。
OO语言引入了安全方便的多态机制,意味着 一切源码依赖,无论何地,均可倒置 。
现在重新观察图 5.1 中的调用树,以及其中的许多源码依赖。一切源码依赖可以通过在其中插入一个接口来完成反转。
在这一机制下,由OO语言开发的系统的软件架构师具有 完全彻底 的对整系统中源码依赖的控制力。他们不再受限于控制流。无论哪个模块是调用者,亦无论哪个模块是被调者,架构师都可以使源码依赖指向任意方向。
这就是power!这就是OO提供的力量。这就是OO真正的内涵——至少从软件架构师的视角看。
你能凭借这一力量做些啥?例如,你可以重排你系统中的源码依赖,使数据库和UI依赖于业务规则。
这意味着UI和数据库可以作为业务规则的插件。这意味着业务规则的源码从不引入UI和数据库。
由此产生的结果,业务规则、UI和数据库可以被编译为三个独立的组件或部署单元(例如jar文件、DLL或Gem文件),均依赖于同一份源码。包含了业务规则的组件不会依赖UI和数据库组件。
反过来,业务规则可以被独立于UI和数据库部署。UI和数据库的改变不会对业务产生任何影响。这些组件都可以被独立部署。
一言以蔽之,当一个组件中的源码发生改变,仅该组件需要被重新部署,这就是 独立部署能力 。
如果你的系统中的模块可以被独立部署,那它们就能被不同团队独立开发,这就是 独立开发能力 。
总结
何为OO?答案纷繁。然而对软件架构师来说却是明晰:OO就是借助多态去完全彻底地控制系统中的源码依赖。它允许架构师创建一个插件式架构,在这样的架构中,包含高层逻辑的模块独立于包含底层细节的模块。底层细节被降级为可独立部署、可独立开发的高层模块的插件。