谁能想到我一个安全专业的人会被后端开发岗捞起来呢 -_-||
按照火星公司的性格,上岸概率不大。这篇先作为draft,暂时不在博客上发表出来。
1 HTTPS的流程?
比较easy的问题,算是看在我的安全经验上来送分的?
此前整理过这个问题 ☞ 秋招 | 一些知识点 (xr_g的博客) ,但是面试的时候稍微有点紧张,忘了一些细节。回答的是基于公钥密码的密钥交换(这个流程比较好记);但实际上HTTPS还有基于ECDHE的密钥交换,当时记得不够清楚,也就没跟面试官讲了。
1.1 为什么HTTPS不用公钥加密通信?
肯定是效率啊!
非对称加密的算法能够得到严谨的安全性证明,但是它的加解密效率比较低;对称加密算法在设计时就充分考虑了计算机硬件的运算优势,所以效率很高。因此,我们一般用非对称加密算法来进行密钥交换,使用交换后的密钥进行对称加密的通信。
2 听过加盐吗?
在存储用户口令的时候,在口令后面附上一些与用户身份相关的值,然后再进行哈希。
这样做的好处是对于不同用户的相同口令,不会得到相同的哈希值,避免了撞库和暴力破解。
当时可没答出撞库和爆破,冷静下来才发现答得有多烂(悲)。
2.1 那一般取什么值来作为盐呢?
呃,嗯,这个……
一般取跟用户身份相关的值?比如用户ID?
事后发现当时少说了一个随机值。
3 听过彩虹表?
大概是预先计算一些明文的哈希值,然后对着得到的哈希值进行比较破解?
巴拉了半天,发现我说的其实就是哈希字典。
然而彩虹表不是这样的!详见 密码破解的利器——彩虹表(rainbow table) - 简书 (jianshu.com) 。
郁闷,又挂一题。
4 听过SYN攻击吗?
SYN Flood?好亲切!
TCP三次握手时,当服务端收到一个SYN,返回ACK+SYN的时候,就为本次连接分配了资源,即所谓的 半开连接 。
而客户端需要完成第三次握手之后,才分配连接资源。
假如有很多客户端,同时向服务端发送SYN,但不完成第三次握手,就会以自身很少的资源消耗、来占用服务端大量的连接资源,使得服务端无法接受其他正常客户端的连接。
4.1 如何防御呢?
一般的WAF都能识别此类攻击。
此外,可以在服务端适当地缩减半开连接的超时时间,即更快地清除没用的半开连接(我在说什么艹)。
还有就是可以用代理服务器先接受连接,这类服务器一般可以针对SYN进行硬件上的优化,也可以通过一定的算法来识别SYN Flood(实在想不出识别的算法,含糊其辞了)。
正解:代理服务器没毛病,可以使用cookie源认证等办法来识别恶意客户端;还有主机上可以设置SYN Cache,先不为半开连接分配资源,等建立连接之后再从cache中取出半开连接的信息,分配资源。
亏我以前还整理过,真正要用的时候想不起来了 -_-||
5 TCP和UDP的区别?
可以再八股一点?
TCP是面向连接的,字节流;UDP是无连接的,报文流。
编程实现上也有一些区别,但是我没用过UDP编程(我又在说什么)。
还有就是TCP的连接是可靠的,有一些办法来保证。
5.1 怎么保证TCP连接可靠?
挖坑埋自己……
想不起来了。
正解:校验、序号、确认、重传。
不说了,有空一定看计网 o(╥﹏╥)o
5.2 假如服务端要接收1、2、3、4、5号包,如何确保有序?
发送窗口和接收窗口吧?
例如服务端收到了2~5号包,而没有收到1号包,此时就发送
ACK=1,告知客户端重传1号包。由于客户端也维持相同的发送窗口,可以只重传1号包而不重传其他。还有冗余ACK,脑子里想到了,当时聊着聊着就忘记说出来了。
5.3 TCP粘包听过吗?
听过,大概就是由于网络原因,把两个包视作了一个包进行处理?
具体是什么情况会出现粘包?
emmm,可能是协议栈实现的时候出了点问题?也可能是网络原因……
正解:其实是因为TCP是字节流的传输,发送端发多少数据和接收端一次收多少数据,没有必然的联系。这就可能出现发送端一次发送
n字节,而接收端一次接收2n字节,两个包就粘到一起了。此外,可能在发送端要等到缓冲区满了才发,那么就有好几个包粘到一起发送的情况。内心OS:其实好像还真是协议栈的实现问题?
详见 粘包问题及解决 - xuchong - 博客园 (cnblogs.com) ,写得真不错!
6 你知道哪些HTTP头?
User-Agent
Referer
XFF
Encode??(记忆模糊了,其实想说Accept-Encoding)
Content-Length
……(被打断)
XFF当时没说上含义,其实是告诉服务端这个请求者的最初始IP。
感谢当年做过的一个简单Web题……
7 I/O 多路复用?
听过,但完全没印象,pass。
8 数据库
8.1 left-join、inner-join、right-join?
完全没答上来……
left-join就是在两个表进行筛选时,完全保留左表的内容;
right-join同理;
inner-join则只保留两个表中都匹配的内容。
left join,right join,inner join,full join之间的区别 - lijingran - 博客园 (cnblogs.com)
8.2 隔离级别?
可算是被我蹲到一个会的。
读未提交:读到其他事务还没提交的数据;
读已提交:顾名思义;
可重复读
串行化。
8.3 隔离级别的区别?
其实隔离级别来源于数据库并行处理事务时会发生的问题。
如脏写、脏读、不可重复读、幻读。
幻读和不可重复读的区别?
不可重复读是针对某个确定数据,而幻读可能是针对不确定的多行数据。
例如,额,额,……(忘了)
9 说一下 fd=fopen() 这个指令在系统中的具体流程?
开始了操作系统部分。
文件的读操作,就是向目标文件的真实设备上发送一个IO请求,这个IO请求经过绑定在这个设备上的多个设备(设备栈)之后,到达文件驱动,然后把文件读取出来,返回。
还有吗?
没了……
后来发现他想问的可能不是驱动,而是API调用的整个过程(中断,保存现场,系统调用,返回文件指针等)。
10 孤儿进程和僵尸进程?
孤儿进程就是指父进程创建子进程后,父进程先死亡,然后子进程就变成了孤儿进程。孤儿进程一般由
init进程接管,会去调用wait方法来回收这些进程。僵尸进程是指父进程创建子进程后,不去管这些子进程了。当子进程结束之后,本来应该由父进程进行回收,但父进程不管它们了,就使得这些子进程的资源停留在系统中。
11 进程切换上下文?
保存一些寄存器的值(ESP、EIP、EBP等)。
产生系统栈、CPU等的开销。
12 冒泡、快排、归并的最好最坏时间复杂度?
冒泡应该都是 O(n^2) ?因为都要进行冒泡。
归并应该都是 O(nlogn) ?因为只需要进行归并。
快排记不清了,最坏是 O(n^2) ,具体场景忘记。
正解:
冒泡最优 O(n) !沃日。
归并都是 O(nlogn) 没毛病。
快排最优 O(nlogn) ,最坏 O(n^2) 。
冒泡最优的情况需要对代码进行优化,如果某次冒泡的时候没有进行交换,说明已经有序,直接返回 (冒泡排序的最优时间复杂度_小君子的博客-CSDN博客_冒泡排序最优时间复杂度)。
快排最优最坏的分析见 (快速排序最好,最坏,平均复杂度分析_weshjiness的专栏-CSDN博客_快排复杂度)。
还有,这个表不错: 常见排序的最好,平均以及最坏时间复杂度_JohnieLi的博客-CSDN博客_排序最好最坏时间复杂度
13 代码题:之字形打印N叉树
如图所示,之字形打印N叉树。
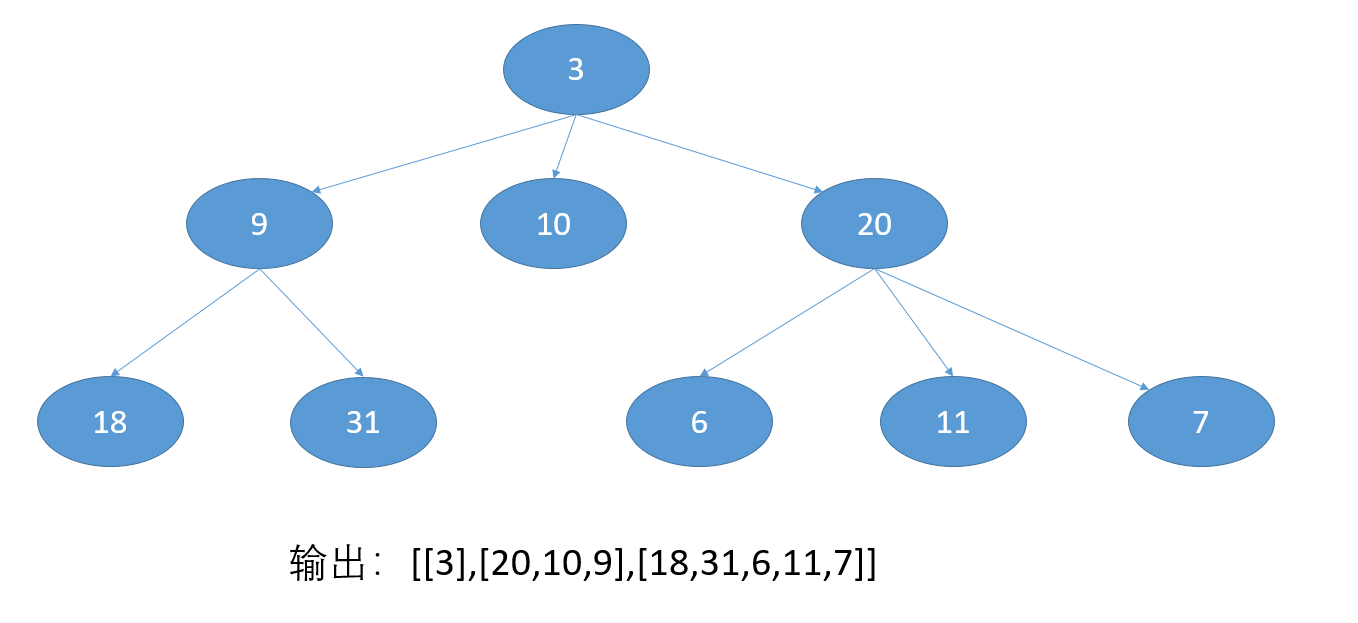
我使用了两个栈来层序遍历。从左到右将子节点入栈,下一层就从右到左输出;反之亦然。
问题在于:如何将子节点 从右到左 入栈呢?
跟面试官聊了聊,他说可以先考虑实现上的方便,那我就用一个
vector来保存子节点,从左到右遍历或从右到左遍历都行。实际上如果使用指针来保存子节点,估计还得开一个临时
vector来存所有子节点,然后再从右到左入栈。