近来修改业务代码的Codecheck,其中有几处移位运算,本来是想着屏蔽检查的,后来被组内大佬建议改用 位域 进行改写,登时觉得惭愧:我所了解的知识竟不至于修改一处小小的代码规范检查?后浅作研究,方觉得这个东西倒也不甚玄妙,此处不予置评,文末方说。
0 何为位域
位域( bit-field ,后文均用 bit-field )是一种特殊的类定义写法,其显式指明了一个类成员所占用的 比特位 ,临近的 bit-field 成员因此有可能在内存上共用或横跨字节 1 。
struct Foo {
unsigned int a;
unsigned int b;
};
struct Bar { // using bit field
unsigned int x : 23;
unsigned int y : 9;
};
int main()
{
std::cout << "sizeof Foo: " << sizeof(Foo) << std::endl <<
"sizeof Bar: " << sizeof(Bar) << std::endl;
}
/** output:
sizeof Foo: 8
sizeof Bar: 4
*/
我们已知 unsigned int 大小是 4 字节,则 Foo 所占用的内存结构如下:
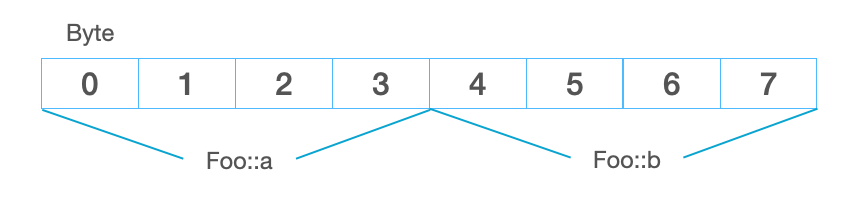
bit-field 写法下的 Bar 所占用的内存结构如下:

可以看到,这里的 Bar::x 和 Bar::y 共用了 字节 2 ,其中 Bar::x 用了这个字节的 7 个比特位,Bar::y 用了这个字节的 1 个比特位。
1 场景
大佬让我使用 bit-field 是因为有这么个场景,需要使用 uint64_t 来表示一个特殊的数据结构,其中高 8 位是一个计数器,用于防止数据重放;原本获取这个数值的代码是这么写的(已脱敏、简化):
uint64_t val = GetVal();
uint8_t e2e = GetE2e(); // counter
val |= static_cast<uint64_t>(e2e) << 56U;
这里的操作其实也没什么毛病,检出的Codecheck本身是个误报,不过,大佬看了这么段代码,觉得这个移位赋值太丑了,于是建议我改用 bit-field 来实现,我最终是这么写的:
struct Bar { // using bit field
uint64_t val : 56;
uint8_t e2e : 8;
};
Bar bar {.val = GetVal(), .e2e = GetE2e()};
看似一切都好,实则有很多东西需要考虑,且看下文分解。
2 转换
原本使用 uint64_t 来表示这么个数据结构,目的是最终把它转为一个 vector<uint8_t> 提供出去;本地用整型维护,是因为这个数据需要频繁地加加减减,如果一开始就维护 vector ,就太难运算了。
因此,改写为 bit-field 之后,仍然必须考虑如何将它转换为 vector<uint8_t> 。
cppreference 提供的Demo里,有个很粗暴的动作是 std::bit_cast 2 ,这个接口会直接把变量所在的地址的一段内存转义为模板指定的那个类型,用在 bit-field 身上大致是这样的:
struct Bar { // using bit field
uint64_t val : 56;
uint8_t e2e : 8;
};
int main()
{
uint64_t localVal = 0x00123456789ABCDEU;
uint8_t localE2e = 0xF0U;
Bar bar {.val = localVal, .e2e = localE2e};
std::cout << std::setfill('0') << std::setw(2) << std::hex << std::bit_cast<uint64_t>(bar) << std::endl;
return 0;
}
/** output
f0123456789abcde
*/
可以看到,这里的输出值实际上是符合我们的预期的,因为这个 bit-field 结构的定义就来自于业务中使用 高 8 位 代表计数器的需求,这里转化出来的 uint64_t 值中,也的确把 0xF0 的部分放到了高位字节。
不过很可惜的是, bit_cast 是C++20以后的特性了,在当前的业务代码中无法使用,穷则思变,大不了自己做类型转换:
struct Bar { // using bit field
uint64_t val : 56;
uint8_t e2e : 8;
};
int main()
{
uint64_t localVal = 0x00123456789ABCDEU;
uint8_t localE2e = 0xF0U;
Bar bar {.val = localVal, .e2e = localE2e};
std::cout << "Using bit_cast: " << std::setfill('0') << std::setw(2) << std::hex << std::bit_cast<uint64_t>(bar) << std::endl;
std::cout << "Using reinterpret_cast: " << std::setfill('0') << std::setw(2) << std::hex <<
*(reinterpret_cast<uint64_t*>(&bar)) << std::endl;
return 0;
}
/**output
Using bit_cast: f0123456789abcde
Using reinterpret_cast: f0123456789abcde
*/
这基本就解决了一切问题,只要把 bit-field 结构转为 uint64_t 传入原有的接口即可。
问题的确是这样解决了的,然而这个特性只这么简单么?
3 内存结构
3.1 早出现的成员在低地址
我们将 Bar 的成员定义换一个顺序,看看输出还是否符合我们的预期:
struct Bar { // using bit field
uint8_t e2e : 8;
uint64_t val : 56;
};
int main()
{
uint64_t localVal = 0x00123456789ABCDEU;
uint8_t localE2e = 0xF0U;
Bar bar {.e2e = localE2e, .val = localVal};
std::cout << "Using bit_cast: " << std::setfill('0') << std::setw(2) << std::hex << std::bit_cast<uint64_t>(bar) << std::endl;
std::cout << "Using reinterpret_cast: " << std::setfill('0') << std::setw(2) << std::hex <<
*(reinterpret_cast<uint64_t*>(&bar)) << std::endl;
return 0;
}
/**output
Using bit_cast: 123456789abcdef0
Using reinterpret_cast: 123456789abcdef0
*/
我们发现,结构体中的计数器部分,转为 uint64_t 之后所在的位置,实际上是不符合预期的。这就表明:我们在定义 bit-field 的时候,越先出现的成员,实际上是在最终转出来的值的 低位 上。
观察我们执行机的字节序 3 :
[drogon@VM-4-4-centos build]$ lscpu | grep -i byte
Byte Order: Little Endian
结合 小端序 的定义,最终可以判断, bit-field 中先定义的成员,就位于 低地址 ,后面的成员,就位于 高地址 ;那么,一个 bit-field 会被转成什么样的数值,就是不确定的了,在小端序机器中,我们最终希望出现在高位的值,就必须放在 bit-field 的后面部分去定义,而大端序机器上,定义则必须相反。
举另一成员较多的结构来佐证我们的发现:
struct Foo {
uint16_t a : 16;
uint16_t b : 16;
uint16_t c : 16;
uint16_t d : 16;
};
int main()
{
uint16_t localA {0x1234U};
uint16_t localB {0x5678U};
uint16_t localC {0x90ABU};
uint16_t localD {0xCDEFU};
Foo foo {.a = localA, .b = localB, .c = localC, .d = localD};
std::cout << "Using reinterpret_cast: " << std::setfill('0') << std::setw(2) << std::hex <<
*(reinterpret_cast<uint64_t*>(&foo)) << std::endl;
return 0;
}
/**output
Using reinterpret_cast: cdef90ab56781234
*/
3.2 每个成员都遵循字节序
我们考虑直接把 Foo 结构所在的内存,按照从低到高的顺序,一个字节一个字节地打出来。这时早前提到的 std::vector<uint8_t> 和 memcpy 就是一个很好的帮手了:
struct Foo {
uint16_t a : 16;
uint16_t b : 16;
uint16_t c : 16;
uint16_t d : 16;
};
int main()
{
uint16_t localA {0x1234U};
uint16_t localB {0x5678U};
uint16_t localC {0x90ABU};
uint16_t localD {0xCDEFU};
Foo foo {.a = localA, .b = localB, .c = localC, .d = localD};
std::cout << "Using reinterpret_cast: " << std::setfill('0') << std::setw(2) << std::hex <<
*(reinterpret_cast<uint64_t*>(&foo)) << std::endl;
std::vector<uint8_t> vec(sizeof(Foo), 0x0U);
memcpy(vec.data(), &foo, sizeof(foo));
std::cout << "Using memcpy: ";
for (auto ele : vec) {
std::cout << std::setfill('0') << std::setw(2) << std::hex << static_cast<uint16_t>(ele);
}
return 0;
}
/**output
Using reinterpret_cast: cdef90ab56781234
Using memcpy: 34127856ab90efcd
*/
memcpy 将 bit-field 结构体的内存直接拷到 vector 中,然后我们逐字节地输出;可以看到, Foo 结构的内存首先遵循 3.1小节 的规则, Foo::a 在低地址,其次,每个成员被赋的值也按照小端序在存储。
不妨再用GDB验证我们的发现:

3.3 再看Demo
我们搞清了 bit-field 内存结构的两个原则,再来看看 cppreference 提供的Demo:
#include <iostream>
#include <cstdint>
#include <bit>
struct S
{
// will usually occupy 2 bytes:
unsigned char b1 : 3; // 1st 3 bits (in 1st byte) are b1
unsigned char : 2; // next 2 bits (in 1st byte) are blocked out as unused
unsigned char b2 : 6; // 6 bits for b2 - doesn't fit into the 1st byte => starts a 2nd
unsigned char b3 : 2; // 2 bits for b3 - next (and final) bits in the 2nd byte
};
int main()
{
std::cout << sizeof(S) << '\n'; // usually prints 2
S s;
// set distinguishable field values
s.b1 = 0b111;
s.b2 = 0b101111;
s.b3 = 0b11;
// show layout of fields in S
auto i = std::bit_cast<std::uint16_t>(s);
// usually prints 1110000011110111
// breakdown is: \_/\/\_/\____/\/
// b1 u a b2 b3
// where "u" marks the unused :2 specified in the struct, and
// "a" marks compiler-added padding to byte-align the next field.
// Byte-alignment is happening because b2's type is declared unsigned char;
// if b2 were declared uint16_t there would be no "a", b2 would abut "u".
for (auto b=i; b; b>>=1) // print LSB-first
std::cout << (b & 1);
std::cout << '\n';
}
2
1110000011110111
这个例子在我最初和同事一块研究的时候,搞得我们云里雾里的,完全不知道这里的输出是怎么回事,实际上万变不离其宗,只消考虑:
-
先定义的成员在低地址,因此变量
s的内存结构就是s.b1~s.b2~s.b3 -
成员的值也遵循小端序,因此对于
s.b2 = 0b101111,它的内存从低到高的比特位其实是反过来的111101 -
bit-field有 匿名成员 和 内存对齐 等机制,由于比较易懂不在本文介绍的重点里,简单理解为使用0来填充一些比特位,使整个结构的大小符合内存分配的规律(如4字节的倍数这样的)
这三点结合起来,可以解释Demo里的 注释 。
对Demo的输出的理解则又要多绕一个弯:这里的 for 循环实际上是 从低位到高位 打印 i 这个变量,这个变量又是 std::bit_cast<uint16_t>(s) 得到的,因此,虽然 i 的内存结构跟 s 是一样的,但它的数值,已经按照小端序的规则转化过了。现在, i 的 低位 实际上是内存的 低地址 ,循环从 低位到高位 打出来的就是内存的 低地址到高地址 ,也就是我们看到的,注释里面的 s 的内存结构。
4 番外
本章摘录一些 bit-field 的其他特性 4 :
-
匿名成员,只定义长度但不提供名字,通常用于把比特位拉齐到
8到整数倍,在 3.3节 中的Demo里有; -
不能 对
bit-field成员取地址,编译会失败,原因很容易理解:成员在内存中可能是 跨字节 的,因此指针没办法定位到这样的成员身上; -
对
bit-field成员赋超出表示范围的值,最终的结果要看编译器的实现(一般是类似整数截断的行为); -
bit-field也可以放到类里,也可以定义public接口对bit-field成员进行操作:
class Foo {
public:
Foo(uint16_t rhsa, uint16_t rhsb) : a(rhsa), b(rhsb) {}
uint16_t GetA() { return static_cast<uint16_t>(a); }
uint16_t GetB() { return static_cast<uint16_t>(b); }
uint32_t GetC() { return c;}
private:
uint16_t a : 5;
uint16_t b : 8;
uint32_t c{0xDEADBEEF}; // common member
};
template<typename T, std::enable_if_t<std::is_unsigned_v<T>, bool> = true>
void LOGX(T val) { std::cout << std::setfill('0') << std::setw(2) << std::hex << val << std::endl; }
template<typename T>
void LOGX(const std::string &desc, T val)
{
std::cout << desc;
LOGX(std::forward<T>(val));
}
int main()
{
std::cout << "sizeof Foo: " << sizeof(Foo) << std::endl; // 内存对齐
Foo foo(0xFF, 0xAB);
LOGX("foo.a: ", foo.GetA()); // 截断
LOGX("foo.b: ", foo.GetB()); // 正常
LOGX("foo.c: ", foo.GetC()); // 默认构造
return 0;
}
/**output
sizeof Foo: 8
foo.a: 1f
foo.b: ab
foo.c: deadbeef
*/
感悟
写完本文不禁感叹,由于字节序的存在,使得要想在实际生产中快速地引入 bit-field 是很难的,对于两三个成员的结构来说尚可以把握,成员一多,每个成员的字节序、每个成员的值的字节序,就成为了令人头痛却又不得不考虑的一个东西了。无怪乎我虽浅看过一些C/C++编程的材料,却直到大佬亲自指点方知有此特性的存在。
假如只是为了缩减结构体所占的内存,且结构体本身又没有特殊的转为数值的诉求,那么使用 bit-field 这样的底层特性是合适的;而假如像本文所说的,总是希望对 bit-field 所在的那块内存进行一些转换,则这个机制的底层原理实在很容易把人绕进去,倒不如乖乖使用虽丑却香的整数位运算去也。
参考资料
-
Bit-field, cppreference, https://en.cppreference.com/w/cpp/language/bit_field ↩︎
-
std::bit_cast, cppreference, https://en.cppreference.com/w/cpp/numeric/bit_cast ↩︎
-
理解字节序, 阮一峰, https://www.ruanyifeng.com/blog/2016/11/byte-order.html ↩︎
-
Bit Fields in C, GeeksforGeeks, https://www.geeksforgeeks.org/bit-fields-c/ ↩︎