今天看的演讲是关于数据驱动设计( Data-oriented Design, DoD )的,真令我大开眼界。这个设计思路的性能收益很高,可读性也很好,实在应该找个机会狠狠落实到工作中。
Vittorio的演讲风格挺干练的,talk is cheap,全程围绕一个小Demo来演绎如何通过DoD实现巨大的性能优化。
1 一个简单的Demo
Demo是一个简单的场景模拟,要求在屏幕上飞过一些 可以喷射粒子 的 火箭 ,并为了更加贴近实际,附加了几点需求:
- 运动模拟:火箭需要模拟出位置、速度、加速度等
- 效果:不同类型的粒子和发射器,支持自定义参数(透明度、大小、旋转角等)
- 实体:为了便于控制单个实体,理论上可以建模为例如火箭+发射器
- 扩展性:便于增加新的实体或效果

一个简单的建模会是这样的(其中深蓝色为实体类,浅蓝色为抽象类):
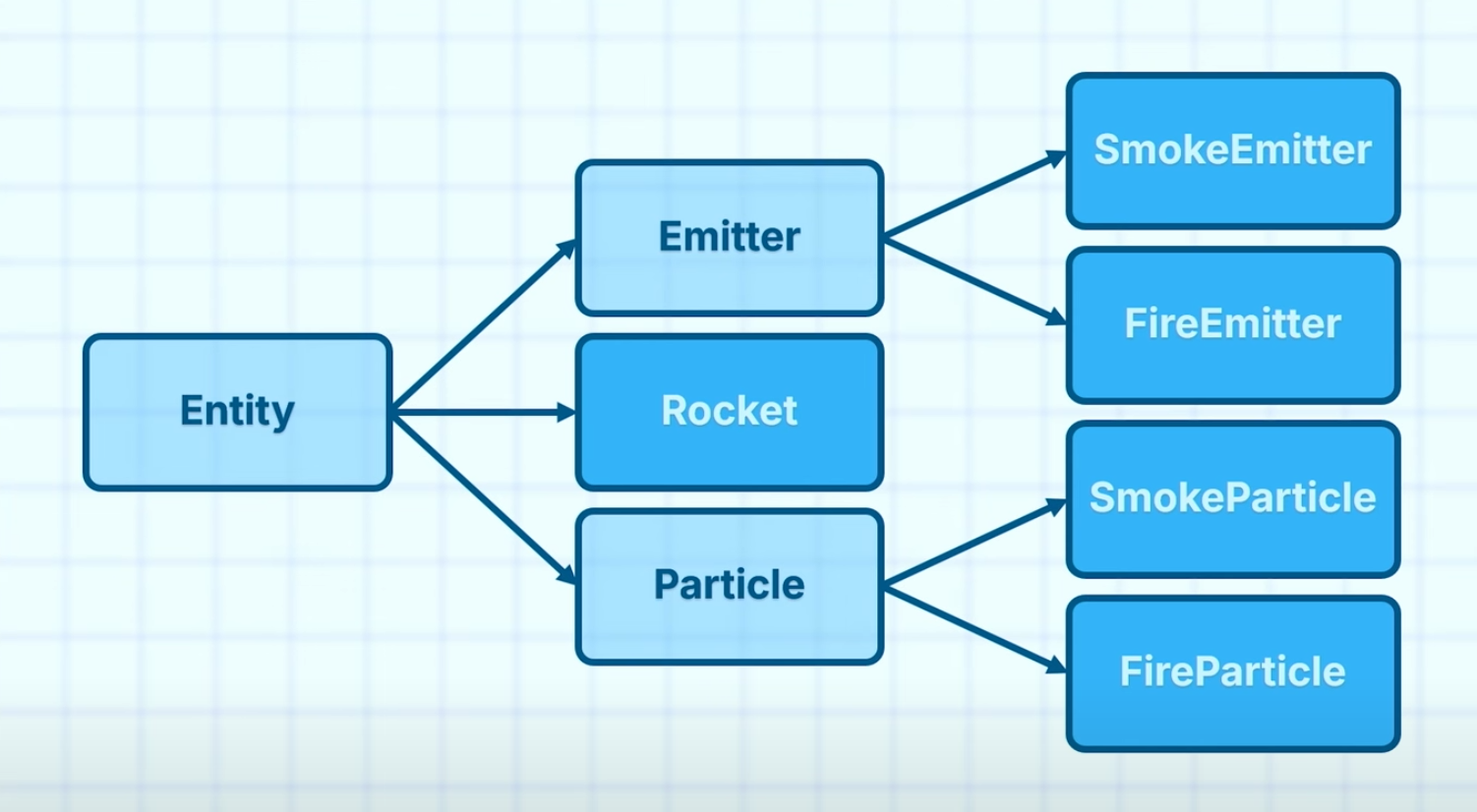
- 场景中所有的对象都是一个 实体
Entity - 发射器和粒子可以有不同类型,如火焰发射器&烟雾发射器,对应火焰粒子&烟雾粒子
对象的实现可能是这样的(结合个人理解,对声明顺序进行了调整,以便呈现思路,其余代码细节均与演讲保持一致):
struct Entity {
// 1 首先实体在我们的设计中是一个抽象类,通常需要虚析构函数
virtual ~Entity() = default;
// 2 实体需要遵循物理规律,因此提供一些物理属性(位置、速度、加速度)
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
// 3 实体需要更新和渲染
virtual void update(float dt)
{
position += velocity * dt;
velocity += acceleration * dt;
}
virtual void draw(sf::RenderTarget&);
// 4 实体需要感知别的实体,因此会引用世界对象,同时,告诉世界自身是否还存活
World& world;
bool alive = true;
};
粒子的实现,在实体基础上增加了大小、透明度和旋转角,同时当透明度降为 0 时,会自动销毁:
struct Particle : Entity {
float scale, scaleRate;
float opacity, opacityChange;
float rotation, angularVelocity;
void update(float dt) override
{
Entity::update(dt);
scale += scaleRate * dt;
opacity += opacityChange * dt;
rotation += angularVelocity * dt;
alive = opacity > 0.0f;
}
};
具体粒子的实现,如烟雾粒子,只是使用特定纹理实现了渲染能力,演讲中没有给出具体实现:
struct SmokeParticle : Particle {
void draw(sf::RenderTarget& target) override
{
// ... draw using smoke texture ...
}
};
所有的实体保存在世界中,世界对象会管理所有实体,并调用每个实体的更新和渲染方法:
struct World {
std::vector<std::unique_ptr<Entity>> entities;
void update(float dt)
{
for (auto& entity : entities)
entity->update(dt);
}
void draw(sf::RenderTarget& target)
{
for (auto& entity : entities)
entity->draw(target);
}
void cleanup()
{
std::erase_if(entities, [](const auto& entity) { return !entity->alive; });
}
};
发射器的功能就是定期发射粒子,而具体发射器的实现,如烟雾发射器,只是生成一个粒子对象,并添加到世界中:
struct Emitter : Entity {
float spawnTimer, spawnRate;
virtual void spawnParticle() = 0;
void update(float dt) override
{
// ... periodically call `spawnParticle()` ...
}
};
struct SmokeEmitter : Emitter {
void spawnParticle() override
{
// 这里的代码和演讲里的代码稍有不同,我认为这个实现才对
// 演讲的代码里把 `world` 当指针用,但实际上在 Entity 的定义中, `world` 是一个引用
world.entities.emplace_back(std::make_unique<SmokeParticle>());
}
};
最后一个实体是火箭,它和发射器的关系是组合关系,它的移动会带着发射器移动:
struct Rocket : Entity {
// 因为能够保证生命周期,所以这里使用裸指针
SmokeEmitter *smokeEmitter = nullptr;
FireEmitter *fireEmitter = nullptr;
Rocket()
{
// ... create emitters ...
}
void update(float dt) override
{
// ... move emitters with rocket ...
}
};
上述的实现有些地方也禁不起严格推敲,例如
Entity::update实现了移动,但Emitter::update行为和它的基类完全不一样… whatever,这个实现还是比较OOP style的
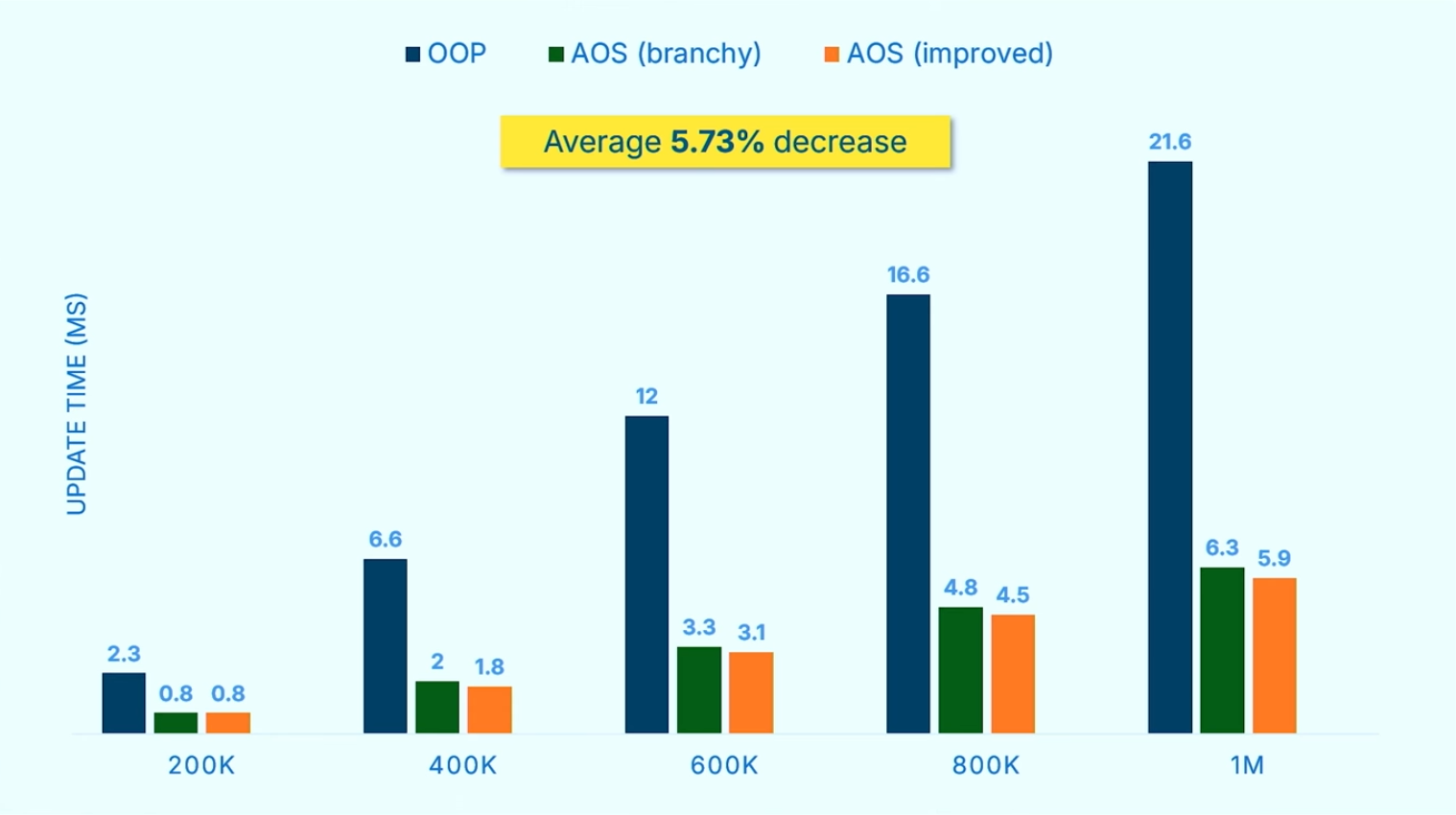
作者的benckmark测试结果如下,横轴为不同实体数量,纵轴为update消耗的时间:
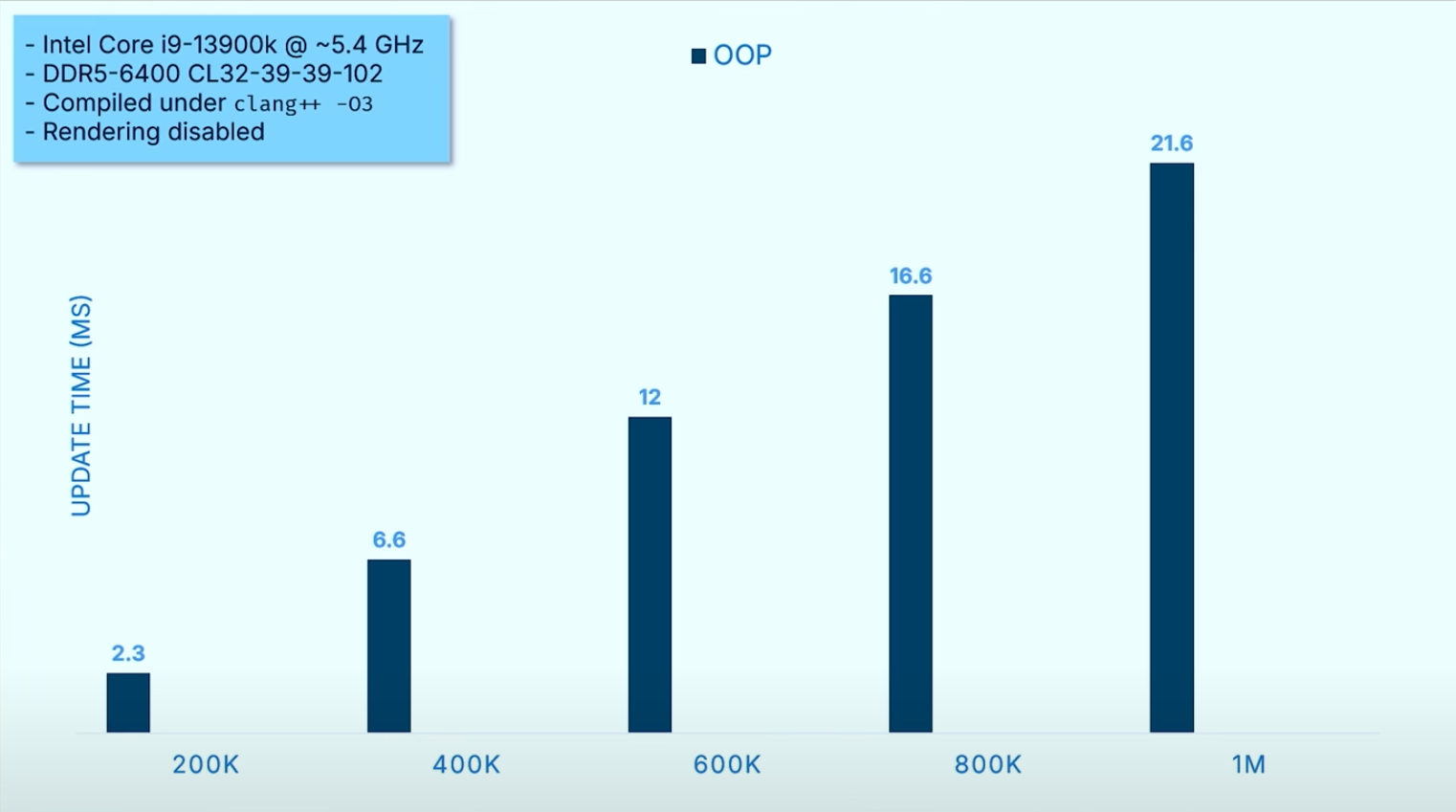
看上去还可以的表现,但又考虑到两个数据:
60FPS = ~16.67ms144FPS = ~6.94ms
😲🥲!这样看来,为了流畅运行,每一帧留给开发者的时间真的非常短,常规实现的性能问题非常之显著。
2 题外话:内存和Cache
这一节不打算跟着演讲详细记录,仅摘录一些重要的点。
- Cache line 是最小的内存传输单元:即使我们只需要一个字节的数据,内存也是按照整行读入的;因此更宜使用连续内存,且按照利于CPU预测的方式进行数据访问;

3 OOP实现的性能问题分析
- 世界对象中使用的是实体的指针,即,内存中实体的分布可能是分散的,这导致了几乎每次迭代都可能产生Cache Miss
- 每次调用实体的
update方法都需要进行虚函数的动态分发(运行时多态,依赖虚表查找真正的实现) - 较多的内存申请/释放

4 设计哲学的对比
从设计哲学来看,最初的实现虽然存在性能问题,但基本上已经符合OOP的设计哲学:

- 世界由对象组成
- 通过消息传递进行交流
- 暴露行为、隐藏数据
- 规划未知的需求
Vittorio说这个 bet (赌注)一词是他精心安排的,我一定程度上同意。OOP的基类,每一个方法都在赌自己对于世界的描述是正确的;后续扩展出来的子类,满足基类的设计则皆大欢喜,不满足基类的设计则拖泥带水地改动。这不是说OOP本身有问题,而是在实践中这太过于考验开发人员的设计水平,谁又能要求每个人都是大pro呢?
相比之下,面向数据的设计哲学可能是这样的:

- 世界由数据组成,代码的作用是把数据从一个状态转换到另一个状态
- 直接操作批量数据
- 暴露数据,集中行为
- 规划当下
转变思路的关键:

- 认识到代码的唯一作用就是进行数据转换
- 认识到数据是核心,而不是需要隐藏起来的东西
- 认识到计算机更喜欢简单、可预测的工作,向计算机提供大段连续的数据
- 认识到设计服务于机器,而非问题的建模
的确比较振聋发聩,尤其是“Design for the machine”,完全是对习惯于OOP的人的一大冲击
5 对Demo的优化
5.1 优化1
- 避免单独的内存请求:干掉指针
- 拉平架构:干掉继承
- 数据和逻辑解耦:实体只是一些数据,世界决定行为
- 将不同的类型存在各自的连续的数组中:从一个基类指针数组切换到若干实际对象的数组
talk is cheap:
// 当前发射器和粒子需要区分烟雾和火焰
// *暂且* 通过一个 `type` 属性来区分,后面会继续优化
enum class ParticleType {
Smoke,
Fire
};
struct Emitter {
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
float spawnTimer, spawnRate;
ParticleType type;
};
struct Particle {
// 数据之间不再有继承关系,尽管这样会带来物理要素的重复,但没太大关系
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
float scale;
float opacity;
float rotation;
float scaleRate;
float opacityChange;
float rotationVelocity;
ParticleType type;
};
struct Rocket {
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
// 火箭不再通过指针来管理发射器,而是通过索引来关联
std::size_t smokeEmitterIndex;
std::size_t fireEmitterIndex;
};
世界对象现在管理数据:
class World {
std::vector<Particle> particles;
std::vector<Rocket> rockets;
// 要点:由于我们的rocket通过索引关联发射器
// 当发射器移除,不应重排内存,而只是将对应槽位置为无效,因此这里使用optional
std::vector<std::optional<Emitter>> emitters;
void addRocket(const Rocket &rocket);
std::size_t addEmitter(const Emitter &emitter);
void update(float dt);
void draw(sf::RenderTarget &target);
void cleanup();
};
世界对象的 update 方法:
void World::update(float dt)
{
for (Particle &particle : particles) {
particle.position += particle.velocity * dt;
particle.velocity += particle.acceleration * dt;
particle.scale += particle.scaleRate * dt;
particle.opacity += particle.opacityChange * dt;
particle.rotation += particle.rotationVelocity * dt;
}
for (std::optional<Emitter> &e : emitters) {
if (!e.has_value())
continue;
e->position += e->velocity * dt;
e->velocity += e->acceleration * dt;
e->spawnTimer += e->spawnRate * dt;
for (; e->spawnTimer >= 1.f; e->spawnTimer -= 1.f)
if (e->type == ParticleType::Smoke)
particles.push_back({...});
else if (e->type == ParticleType::Fire)
particles.push_back({...});
}
for (Rocket &rocket : rockets) {
rocket.position += rocket.velocity * dt;
rocket.velocity += rocket.acceleration * dt;
if (std::optional<Emitter> &se = emitters[rocket.smokeEmitterIndex])
se->position = rocket.position - sf::Vector2f(12.f, 0.f);
if (std::optional<Emitter> &fe = emitters[rocket.fireEmitterIndex])
fe->position = rocket.position - sf::Vector2f(12.f, 0.f);
}
}
添加发射器:
std::size_t World::addEmitter(const Emitter &emitter)
{
for (std::size_t i = 0; i < emitters.size(); ++i)
if (!emitters[i].has_value()) {
emitters[i] = emitter;
return i;
}
emitters.push_back(emitter);
return emitters.size() - 1;
}
清理:
void World::cleanup()
{
// 清理粒子
std::erase_if(particles, [](const Particle &p) {
return p.opacity <= 0.f;
});
// 清理火箭,发射器的生命周期跟着火箭
std::erase_if(rockets, [](const Rocket &r) {
if (r.position.x < bounds.x)
return false;
// 清理对应的发射器
emitters[r.smokeEmitterIndex].reset();
emitters[r.fireEmitterIndex].reset();
return true; // 超出屏幕范围
});
}
可怕的性能提升😲🫡:
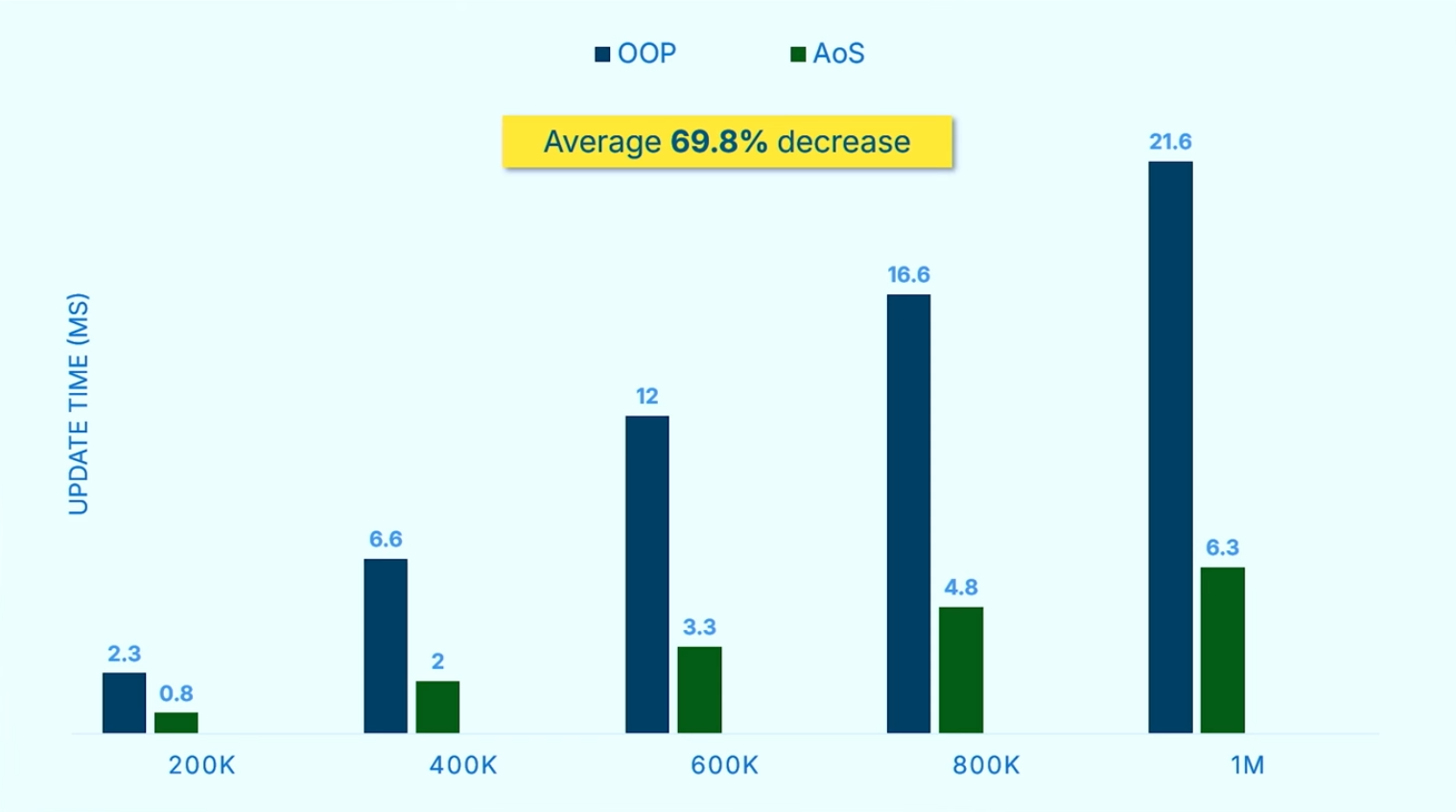
扩展性
在某些扩展需求场景下,DoD还有显著的优势。
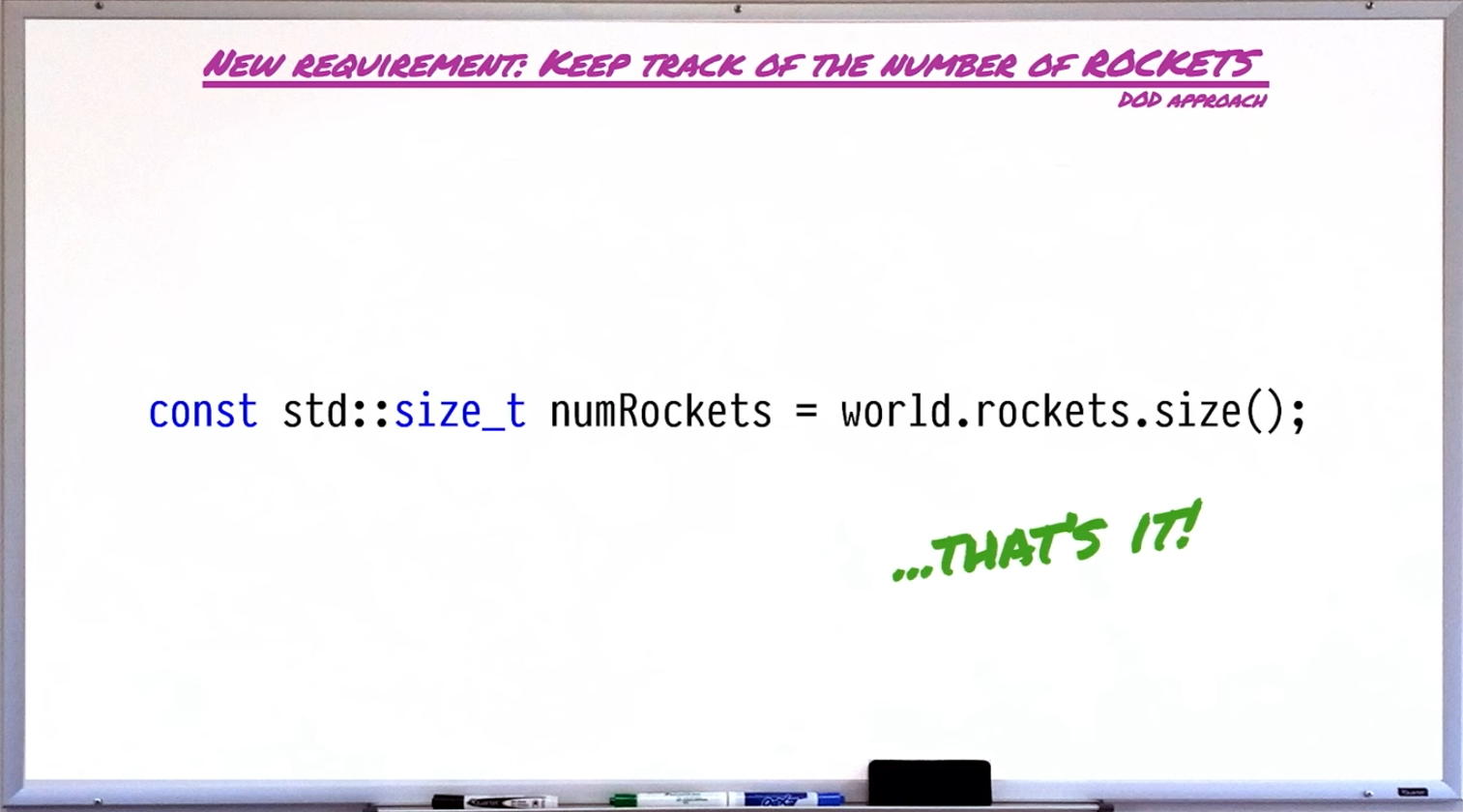
例如,当我们需要跟踪火箭的数量时,OOP不是太慢、就是会打破各种面向对象的原则,而DoD一行秒了:

例如,对多线程的支持。OOP的实现实际上很难支持并发,毕竟每个对象都对全局的对象产生影响,而DoD的朴素循环天然支持并发操作:


可读性
至于代码的可读性,DoD的代码比OOP更直白,更松耦合,更易维护。


✔️感悟:在工作中的确发现OOP的代码在复杂的继承关系出现时会变成一坨。接触新功能模块时点出一个抽象类的所有子类一个个看过去,还要在一边时刻记着调用点的上下文,不知道带走了我多少个脑细胞… 😶🌫️
5.2 优化2
- 在高频循环中避免分支,以免缓存命中率下降
- 减小公共类型的体积,使得缓存可以塞下更多的对象
// 【5.2】相比于5.1,不再需要发射器/粒子类型,将由世界对象来分类
struct Emitter {
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
float spawnTimer, spawnRate;
};
struct Particle {
// 数据之间不再有继承关系,尽管这样会带来字段的重复,但没太大关系
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
float scale;
float opacity;
float rotation;
float scaleRate;
float opacityChange;
float rotationVelocity;
};
struct Rocket {
sf::Vector2f position;
sf::Vector2f velocity;
sf::Vector2f acceleration;
// 【5.2】作者指出5.1的 size_t 占用的大小太大(64比特),实际只需要 u16
// 说实话,我感觉65536个发射器好像不满足benchmark上百万个火箭的需要,
// 可能是因为一个屏没办法同时存在这么多数据,内存是循环利用的,才能做这种改造?
std::uint16_t smokeEmitterIndex;
std::uint16_t fireEmitterIndex;
};
由于我们不再进行发射器/粒子的分类,世界对象的数据管理会变得精细:
class World {
// 【5.2】相比于5.1,这里对数组的管理更细
std::vector<Particle> smokeParticles;
std::vector<Particle> fireParticles;
std::vector<Rocket> rockets;
std::vector<std::optional<Emitter>> smokeEmitters;
std::vector<std::optional<Emitter>> fireEmitters;
void addRocket(const Rocket &rocket);
// // 【5.2】相比于5.1,这里支持指定要添加的数组
std::size_t addEmitter(auto& targetVec, const Emitter &emitter);
void update(float dt);
void draw(sf::RenderTarget &target);
void cleanup();
};
优化后的更新函数:
void World::update(float dt)
{
auto updateParticles = [&](Particle& particles) {
particle.position += particle.velocity * dt;
particle.velocity += particle.acceleration * dt;
particle.scale += particle.scaleRate * dt;
particle.opacity += particle.opacityChange * dt;
particle.rotation += particle.rotationVelocity * dt;
};
for (Particle &particle : smokeParticles) updateParticles(particle);
for (Particle &particle : fireParticles) updateParticles(particle);
auto updateEmitter = [&](std::optional<Emitter>& e, auto&& fSpawn)
{
if (!e.has_value())
return;
e->position += e->velocity * dt;
e->velocity += e->acceleration * dt;
e->spawnTimer += e->spawnRate * dt;
for (; e->spawnTimer >= 1.f; e->spawnTimer -= 1.f)
fSpawn();
};
for (std::optional<Emitter>& e : smokeEmitters)
updateEmitter(e, [&] { smokeParticles.emplace_back(...); });
for (std::optional<Emitter>& e : fireEmitters)
updateEmitter(e, [&] { fireParticles.emplace_back(...); });
}
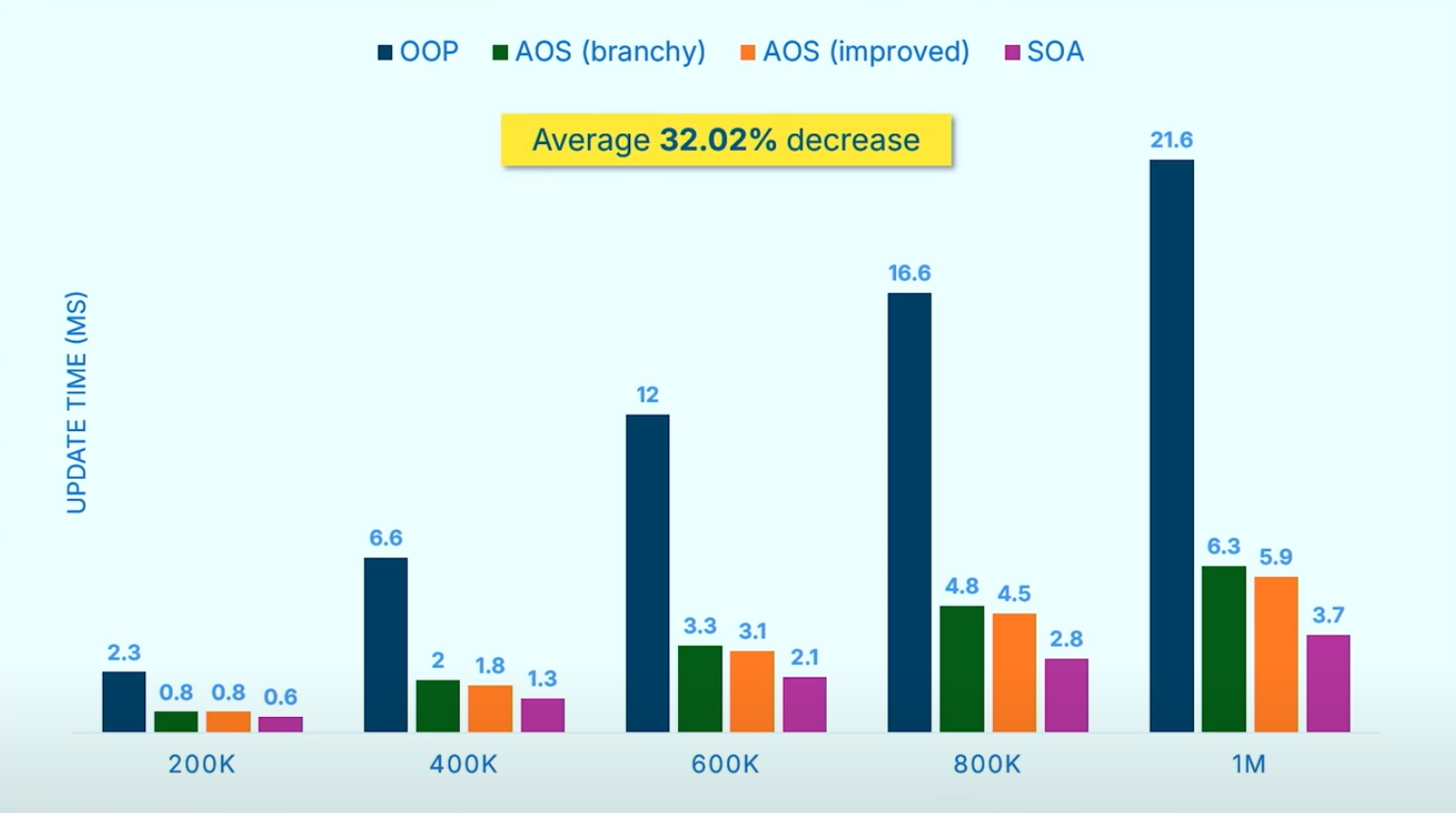
性能提升并不很大,原因是对于作者的benchmark测试来说,性能瓶颈已经不在于数据的安排,而在于更新particle。作者自陈,优化后的数据结构在渲染时带来了12%的性能提升。
5.3 优化3
- 从 Array of Structs (对象数组)改成 Struct of Arrays (数组对象)
不敲代码了:

相比于AoS,SoA存在如下方面的提升:

- 没有对象内部的 padding 。我们知道一个数据结构内部的字段不等长,因此AoS单元之间会由于每个对象内部的对齐,存在一些空内存
- 更灵活的字段加载。当我们只需要访问一个对象的一个字段时,AoS会需要逐个加载整个对象,而SoA能够批量加载所有对象的这个字段,不需要加载其余无关字段。(注、我的理解,这实际上需要和数据处理逻辑部分深度联系,即,可能需要实现字段级别的批处理时,这种特性的优势会比较明显,反之则是劣势)
- 更好地支持向量化操作。这里主要也是指便于进行字段级别的批处理,在这种应用场景下SIMD(单指令多数据)会进一步带来性能提升
拓展阅读:
[1] 理解SIMD技术,高效并行计算的利器,https://blog.csdn.net/qq_34068440/article/details/139636268
改造为SoA的实现如下:
struct ParticleSoA {
std::vector<sf::Vector2f> positions;
std::vector<sf::Vector2f> velocitys;
std::vector<sf::Vector2f> accelerations;
std::vector<float> scales;
std::vector<float> opacities;
std::vector<float> rotations;
std::vector<float> scaleRates;
std::vector<float> opacityChanges;
std::vector<float> rotationVelocities;
void forAllVectors(auto&& f) {
f(positions);
f(velocitys);
f(accelerations);
f(scales);
f(opacities);
f(rotations);
f(scaleRates);
f(opacityChanges);
f(rotationVelocities);
}
};
struct World {
// 【5.3】相比于5.2,这里粒子类型使用了SoA
ParticleSoA smokeParticles;
ParticleSoA fireParticles;
// 【5.3】这里不做改造的原因是性能瓶颈不在这里
std::vector<Rocket> rockets;
std::vector<std::optional<Emitter>> smokeEmitters;
std::vector<std::optional<Emitter>> fireEmitters;
// ...
};
改造后的更新函数:
void World::update(float dt)
{
// 【5.3】相比于5.2,这里使用了SoA
auto updateParticles = [&](ParticleSoA& soa) {
const auto nParticles = soa.positions.size();
// 迭代里面的操作是混合的,主要是Vittorio做的实验发现这里混合迭代性能较好
for (std::size_t i = 0; i < nParticles; ++i) {
soa.velocitys[i] += soa.accelerations[i] * dt;
soa.positions[i] += soa.velocitys[i] * dt;
soa.scales[i] += soa.scaleRates[i] * dt;
soa.opacities[i] += soa.opacityChanges[i] * dt;
soa.rotations[i] += soa.rotationVelocities[i] * dt;
}
};
updateParticles(smokeParticles);
updateParticles(fireParticles);
for (std::optional<Emitter>& e : smokeEmitters) {
if (!e.has_value())
continue;
e->position += e->velocity * dt;
e->velocity += e->acceleration * dt;
e->spawnTimer += e->spawnRate * dt;
for (; e->spawnTimer >= 1.f; e->spawnTimer -= 1.f) {
// 【5.3】这里不得不分别对每个字段单独添加,比较恶心但没办法 🫥
// 也许SoA对象自行封装一个emplace函数,来完成这个操作会更好,不重要~
smokeParticles.positions.emplace_back(...);
smokeParticles.velocitys.emplace_back(...);
// ...
smokeParticles.rotationVelocities.emplace_back(...);
}
}
}
清理函数也是带有SoA风格的:
// 首先定义一个简单的帮助方法
void soaEraseIf(ParticleSoA& soa, auto&& predicate)
{
std::size_t n = soa.positions.size();
std::size_t i = 0u;
while (i < n) {
if (!predicate(soa, i))
{
++i;
continue;
}
// 🔖这里很妙,需细品
--n;
soa.forAllVectors([&](auto& vec) { vec[i] = vec[n]; });
}
soa.forAllVectors([&](auto& vec) { vec.resize(n); });
}
void World::cleanup()
{
auto hasNegativeOpacity = [](const ParticleSoA& soa, std::size_t i) {
return soa.opacities[i] <= 0.f;
};
soaEraseIf(smokeParticles, hasNegativeOpacity);
soaEraseIf(fireParticles, hasNegativeOpacity);
// ...
}
收益也是非常的amazing:
对于SoA分为多个数组字段所带来的不易维护问题,Vittorio提供了一些反射实现:
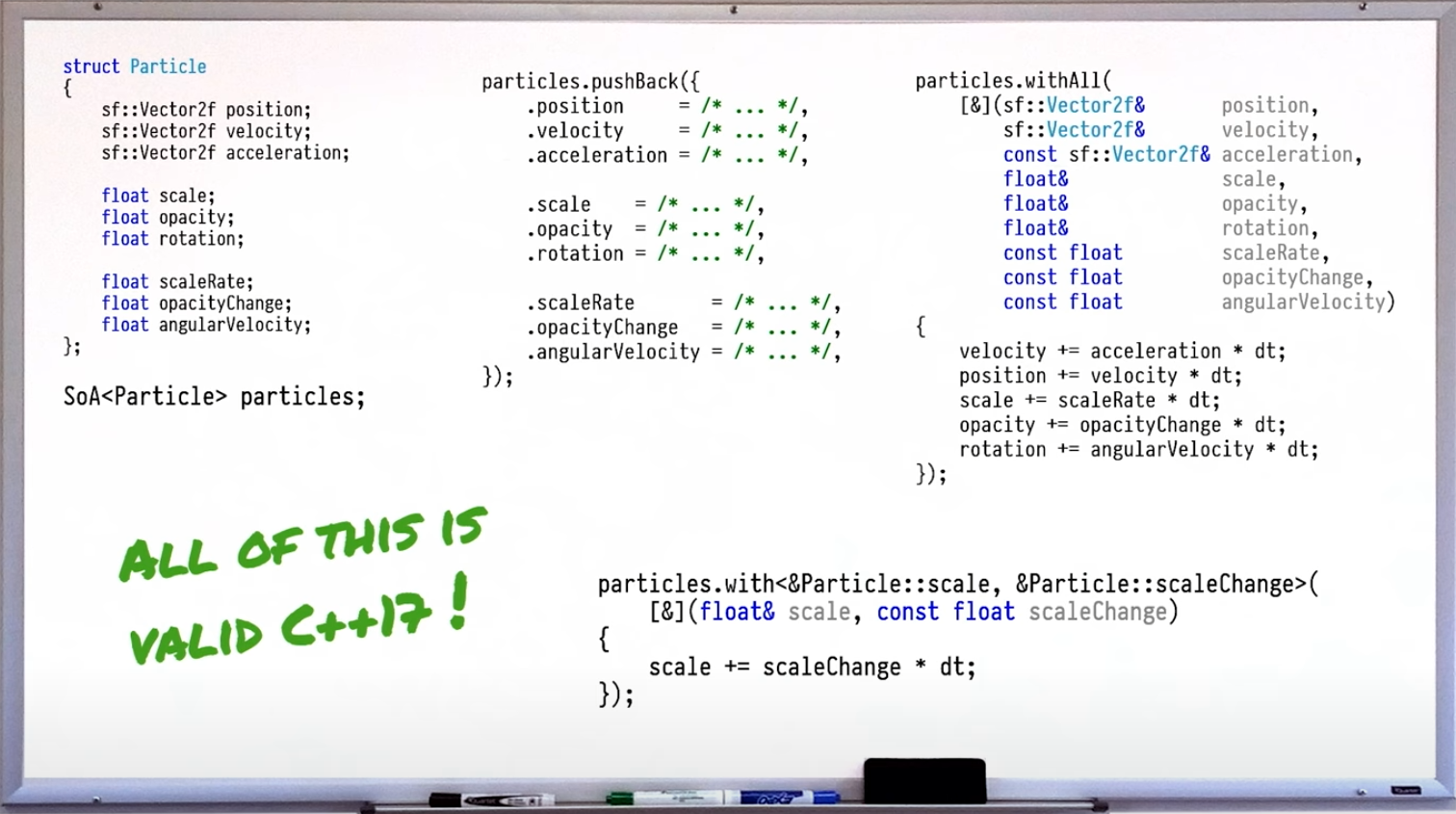
并提及这些实现将在C++26有真正的官方支持~😲
5.4 one more thing
- DoD和SoA并没有直接联系,SoA只是一种优化策略而非终极答案

- DoD也并非终极答案,OOP在更上层的业务中仍起到优秀的抽象作用(注、OOP是外壳,DoD是引擎,这句话个人觉得非常好地描述了两者的合适的关系)

6 总结
- 考量性能于最初
- 扁平、精简的数据结构
- 妥当的分类而非各种类型标识
- 在需要批处理时考虑SoA

Data drives design
- 数据是设计的核心驱动力。这意味着在进行系统或代码设计时,应以实际的数据结构、数据流和使用场景为依据,而不是凭空想象或遵循固定模式。
Target the machine
- 编程的目标是让机器高效运行。强调要关注底层硬件和执行效率,编写能够被机器高效执行的代码,避免过度抽象或不必要的开销。
It’s a spectrum, not dogma
- 软件开发中的各种方法和技术是一个连续谱系,而非非黑即白的教条。鼓励灵活选择适合当前场景的技术方案,不盲目追随某种“最佳实践”。
Embrace Modern C++
- 积极采用现代C++(如C++11及以上版本)的新特性,例如智能指针、lambda表达式、范围for循环等,以提升代码的安全性、可读性和性能。
Pragmatism wins
- 实用主义胜出。最终决定因素是实际效果:是否解决了问题、是否易于维护、是否高效稳定。不要为了追求“优雅”而牺牲实用性。
7 Q&A
Q&A环节,一些问题也颇有启发,浅做记录(记录我理解到的意思而非忠实地翻译问答对话)。
Q:我认为一些习于面向对象的程序员会认为DoD丢失了一些对象间的联系,例如在OOP中 Rocket 和 Emitter 有着清晰的联系,而DoD中这种联系似乎丢失了。对此你怎么看?
A:仅仅观察数据本身的话,我能get到这个问题点。我想指出虽然我们在示例中使用整型索引进行关联性的表达,但实际也可以使用一些 handle 或强类型定义来使得关联性的表达更清晰。另一方面,我觉得当我们操作数据时,这种联系实际上是变清晰而非减弱,当我们阅读 update 中的循环时,我们不止知道 Emitter 和 Rocket 之间存在联系,还知道这种联系是为了什么、产生了什么作用。因此,在这种视角下我们得大于失。
Q:你如何比较DoD和OOP二者之间的可测试性( testability )?
A:我认为DoD(给可测试性)带来了一些很好的收益,例如由于我们的一切都只是数据,我们可以很简单地构造、存储、加载不同的测试数据,而OOP相对来说就没有那么简单地能对对象进行序列化/反序列化的操作。然而OOP仍在一些地方表现更好,例如mocking或依赖注入。因此需要将OOP应用在合适的层级(即前面提到的较高的层级)。
Q:我感觉到似乎批量处理型的任务更能取得DoD的所有益处,你如何看待非批量处理型的任务,例如随机访问或仅处理少数铺展开的实体?
A:依然取决于你的需求,正如演讲中所说,也有很多非常成功的游戏或应用不必关注这些东西(指DoD)。在运用DoD时,如果你的数据天然是一种图或类似的结构,处理起来就需要更巧妙一些,因为它们不像我们的demo那么简单且符合直觉,但DoD仍然有地方施展身手。例如当你在层序遍历一棵树的时候,节点可能可以组织为一个数组(以得到性能收益),因为遍历的顺序是明确的。我的建议仍然是当性能是一项关键需求,且你希望确保你的架构是高效的,此时应考虑数据访问的方式,并把数据组织为使得缓存命中的几率最大化的形式。
Q:当你把数据组织为扁平形式,实际上是产生了一些重复数据,而似乎不如简单地继承自基类。此种做法是否有弊端?毕竟后者使得数据没有重复,内存只有一份。
A:这会取决于你希望表达到多清晰。如果我直接看一个结构,我希望能够直接看到这个东西就有这么多字段,而如果你继承了,阅读代码时就需要再往上翻一层,虽问题不大,毕竟也是一个额外步骤。另一方面是,一旦引入继承关系,就有人可能开始依赖这层关系,使得你对继承体系中的代码修改变得困难,引入了一定的耦合。